


Introducción
La Ciencia de Datos es un campo que está ganando cada vez más notoriedad; pequeñas y grandes empresas, como Netflix, Airbnb y Google, ya están basando sus decisiones en datos. En este escenario, el lenguaje Python es bastante utilizado debido a su versatilidad y simplicidad, contando con una amplia cantidad de bibliotecas, entre ellas, Pandas, una de las herramientas esenciales cuando se habla de Ciencia de Datos.
En este artículo, vamos a conocer la biblioteca Pandas, comprender sus estructuras básicas y también cómo instalar la herramienta.
¿Pero qué exactamente es Pandas?
¿Qué es Pandas?

Pandas es una biblioteca para Ciencia de Datos de código abierto (open source), construida sobre el lenguaje Python, y que proporciona un enfoque rápido y flexible, con estructuras robustas para trabajar con datos relacionales (o etiquetados), y todo eso de manera sencilla y intuitiva.
A pesar de que el nombre de la biblioteca está asociado al mamífero de la familia Ursidae, al igual que Python está asociado erróneamente con la especie de cobra, el nombre de la biblioteca Pandas deriva del término Panel Data, un concepto en inglés relacionado con el campo de estudio de la econometría.
De manera general, Pandas puede ser utilizado para diversas actividades y procesos, entre ellos: limpieza y tratamiento de datos, análisis exploratorio de datos (EDA), soporte en actividades de Machine Learning, consultas y queries en bases de datos relacionales, visualizaciones de datos, web scraping y mucho más. Además de eso, también posee una excelente integración con varias otras bibliotecas muy utilizadas en Ciencia de Datos, como: Numpy, Scikit-Learn, Seaborn, Altair, Matplotlib, Plotly, Scipy y otras.
¿Cómo funciona Pandas?
Dentro del paquete Pandas, tenemos dos objetos primarios importantes: las Series y los DataFrames. Y para comprender un poco mejor sobre estas estructuras, vamos a utilizar como ejemplo un conjunto de datos llamado iris, que contiene información sobre características de especies de las flores de Íris.
Series
Las Series son objetos de tipo array unidimensional, con un eje de etiquetas, también llamado index, que es responsable de identificar cada registro. Un ejemplo de Series en Pandas se encuentra en el conjunto de datos Iris cuando aislamos una de las variables para su visualización, por ejemplo, la longitud del pétalo (PetalLengthCm), donde podemos observar el siguiente formato:
0 1.4
1 1.4
2 1.3
3 1.5
4 1.4
...
145 5.2
146 5.0
147 5.2
148 5.4
149 5.1
Name: PetalLengthCm, Length: 150, dtype: float64
La columna de números a la izquierda es el índice, y los datos se presentan a la derecha. Al final de la presentación, hay una pequeña descripción del nombre, formato y tipo de datos presentes en la Serie.
DataFrame
Los DataFrames son objetos bidimensionales, de tamaño variable. Su formato es similar a una tabla, donde los datos se organizan en filas y columnas. Además, mientras que podemos pensar en las Series como una única columna, el DataFrame sería una colección de varias Series bajo un mismo índice. La estructura del DataFrame se presenta en la siguiente imagen:
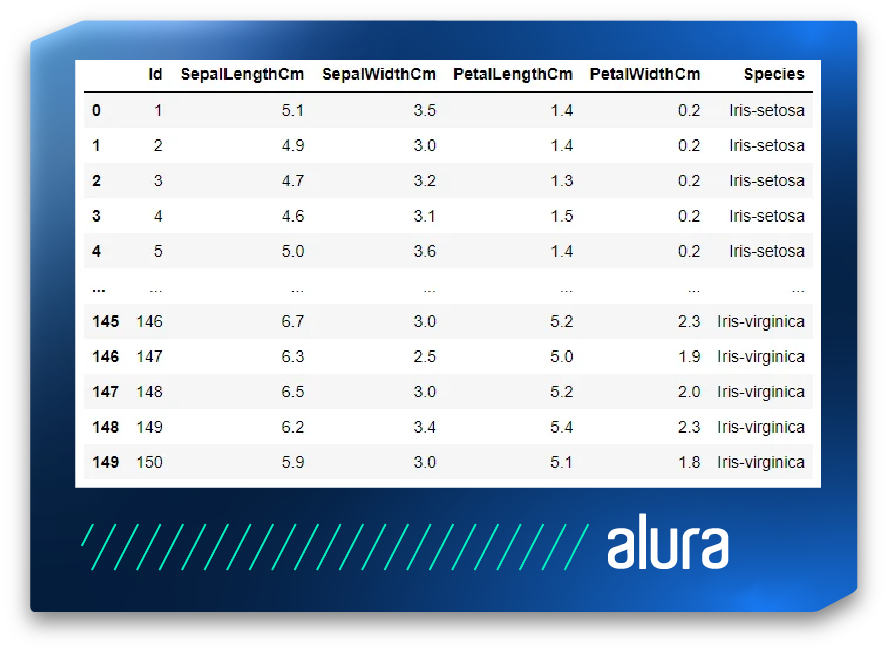
Podemos trabajar con la creación de cada una de estas estructuras utilizando los métodos de Pandas (pandas.DataFrame y pandas.Series) sobre estructuras nativas de Python (como listas, arrays y diccionarios). También podemos trabajar con la lectura y escritura de varios tipos de archivos de datos, como:
Pandas y el Excel

Debido a la adopción del paquete Office de Microsoft, que incluye el editor de hojas de cálculo Excel, surgen discusiones sobre por qué utilizar Pandas. Existen diferencias en las propuestas de cada software. Además de que Pandas es una solución de código abierto y no propietaria, a diferencia de Excel, también es posible observar diferencias en la cantidad de información que cada uno puede manejar.
En Excel, el límite de construcción de las tablas es de 1.048.576 filas por 16.384 columnas. En cambio, en Pandas, la limitación está basada en la cantidad de memoria disponible, lo que nos permite tener una gran variedad de filas y columnas siempre que la memoria asignada no exceda la cantidad disponible en su computadora.
Conocer los límites de cada herramienta se vuelve interesante cuando surge la necesidad de trabajar con conjuntos de datos más grandes, y incluso en casos extremos que fácilmente superan millones de registros, como en el escenario de Big Data.
Sin embargo, aunque estos software tienen propuestas diferentes, también pueden ser utilizados de manera conjunta, ya que Pandas ofrece compatibilidad con los archivos de Excel, tanto en la creación, la lectura como la escritura.
¿Cómo se utiliza Pandas?
En el día a día de un científico de datos, Pandas se utiliza bastante junto con los notebooks interactivos de Python (archivos con extensión .ipynb), como Jupyter Notebook, en los cuales también se basa Google Colab. La idea principal es aprovechar la buena presentación del código y de sus salidas, explorando la practicidad del modo interactivo, mientras se escribe el código y se observa rápidamente la salida, como se muestra en la siguiente imagen:
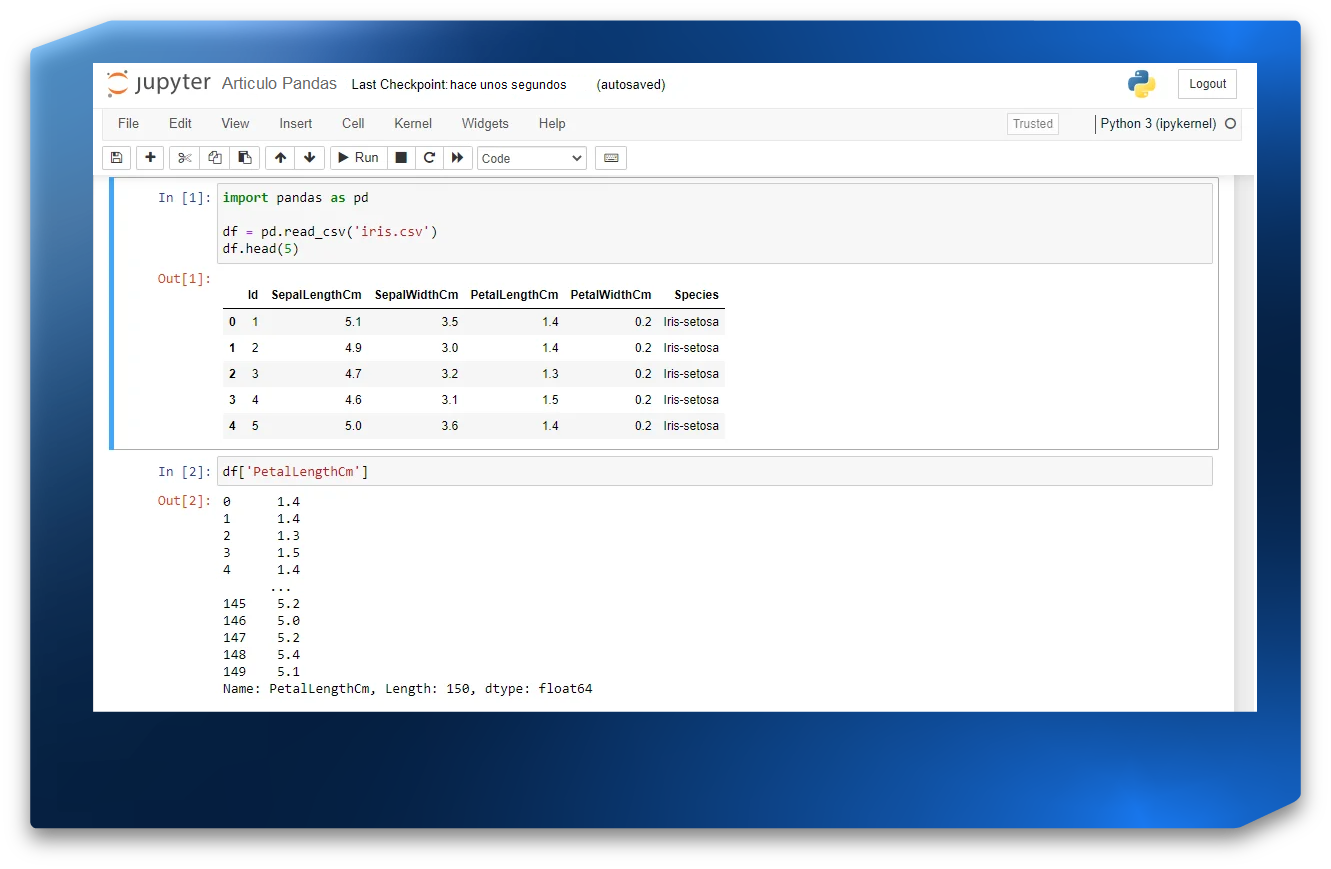
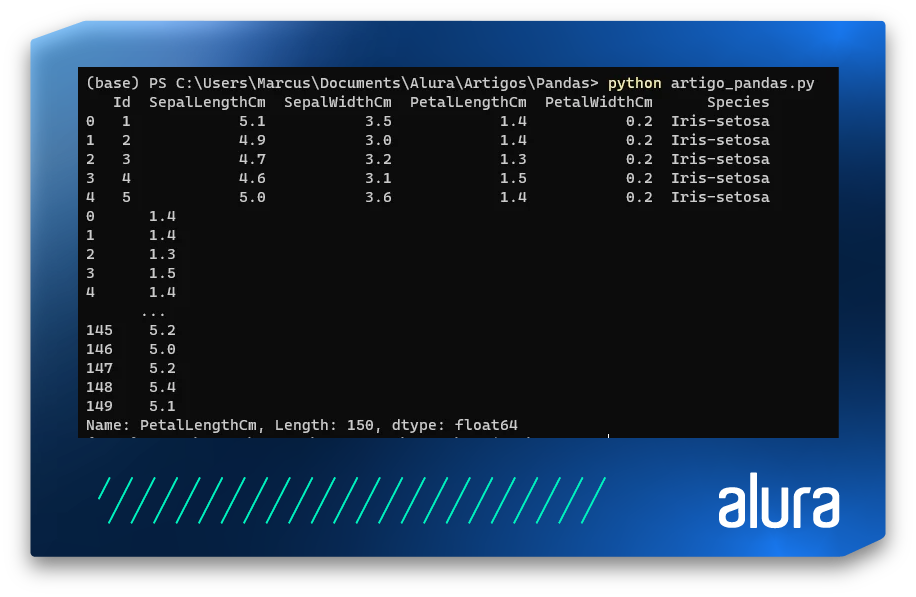
Además de los Jupyter Notebooks, también es posible trabajar con scripts Python comunes (archivos .py). La diferencia es que la salida de todos los fragmentos de código se coloca en el terminal sin distinción, uno tras otro, y en formato raw (crudo). El ejemplo a continuación muestra cómo sería la misma salida, en un script equivalente, en el terminal:
En este episodio de Alura Tips, el profesor Álvaro Camacho habla con Gabriela Aguiar, Scrum Master de Alura Latam, sobre Jupyter Notebook, explorando sus ventajas y usos en el análisis de datos.
Instalación de Pandas
La manera más sencilla de instalar, según la propia documentación de Pandas, es instalando la distribución de Anaconda.

Anaconda es un entorno de desarrollo orientado a la Ciencia de Datos con Python y R, que trae instaladas varias bibliotecas y software de uso popular en el campo. Entre las bibliotecas instaladas, también está Pandas. Puedes aprender cómo instalar Anaconda en Windows a través de la documentación oficial de Anaconda.
Otra manera común de instalar Pandas es utilizando PIP, el sistema de gestión de paquetes de Python.
Una vez que hayas descargado Python desde el sitio oficial, puedes seguir los siguientes pasos:
Atención: Si tienes más de un disco duro en tu máquina, asegúrate de que la instalación se esté realizando en el mismo disco donde se instaló Python.
Para empezar, debemos abrir el Símbolo del Sistema de tu sistema operativo. En Windows, presiona las teclas de acceso rápido Windows + R, escribe "Símbolo del Sistema" y haz clic en la opción "Ejecutar como administrador":
El Símbolo del Sistema se abrirá y aparecerá la pantalla negra del terminal. En este momento, podemos verificar la versión de Python instalada en la máquina con el comando
python --versiony asegurarnos de que podemos continuar:python --versionPython 3.12.0Si aún no tienes PIP instalado en la máquina, puedes descargarlo como un módulo nativo de Python con el siguiente comando:
python -m ensurepip --upgradeY ahora que ya tenemos PIP instalado en la máquina, podemos usarlo para instalar Pandas con el comando:
pip install pandas¡Listo! Ahora ya tienes Pandas instalado en la máquina.
Conclusión
Si deseas sumergirte aún más en los contenidos de Pandas y Ciencia de Datos, aquí en Alura Latam tenemos la Formación Python para Data Science. La formación aborda las principales herramientas utilizadas en Ciencia de Datos con Python, como Pandas, NumPy, Matplotlib, Seaborn y mucho más. En ella, construimos varios proyectos prácticos para completar tu portafolio como profesional de datos.
Créditos
Contenido:
- Marcus Almeida
Producción técnica:
- Rodrigo Dias
Producción didáctica:
- Thaís de Faria
Diseñador gráfico:
- Alysson Manso
Este articulo fue traducido y adaptado por Ingrid Silva
Marcus Almeida
Estudiante de Ingeniería Eléctrica en el Instituto Federal de Maranhão. Trabajó como parte del equipo Scuba de la Escuela de Datos en Alura, enfocado en contenido de Data Science, Machine Learning, Python y SQL. Le encanta hablar sobre tecnología, el universo geek, los videojuegos y también aprender cosas nuevas.
