


Introducción
¿Alguna vez has pensado en poder convertir tu proyecto de datos en una aplicación web utilizando únicamente el lenguaje Python? Streamlit es un marco de código abierto creado específicamente para ayudar a los científicos de datos a poner sus proyectos en producción sin necesidad de conocer herramientas de implementación de aplicaciones o de front-end.
A través de este framework es posible transformar un proyecto de ciencia de datos y aprendizaje automático en una aplicación interactiva. Para esta aplicación, se genera una URL pública que, al compartirse, permite que cualquier persona pueda acceder a ella y utilizarla sin necesidad de conocer el código que hay detrás de ella.
Considerando todas estas características de Streamlit, esta herramienta se convierte en una excelente manera de presentar proyectos técnicos a personas que son legos en el área. Además de hacer que la presentación luzca muy profesional.
Para el desarrollo del siguiente proyecto se utilizará el editor de código de Visual Studio Code.
Configuración del entorno
Para comenzar, crearemos un entorno virtual donde instalaremos las librerías que se utilizarán en el desarrollo del proyecto. Podemos crear una carpeta donde se almacenarán los archivos de nuestro proyecto, llamarla "Article_Streamlit", por ejemplo, y luego acceder a ella a través del editor de código.
En la carpeta podemos crear un archivo llamado requirements.txt para colocar las librerías que queremos instalar en nuestro entorno virtual:
pandas
seaborn
matplotlib
streamlit
Posteriormente, para crear, activar e instalar los paquetes en el entorno virtual, podemos abrir la terminal del propio editor de texto mediante el atajo Ctrl + J y ejecutar los siguientes comandos:
Creando el entorno :
python -m venv venv
Activando el entorno :
En Windows:
venv\Scripts\activate
En Linux o Mac:
source venv/bin/activate
Instalación de paquetes desde requirements.txt :
pip install -r requirements.txt
¡Con el entorno configurado ya podemos empezar a desarrollar nuestro proyecto!
Creando la primera aplicación usando Streamlit
Dentro de la carpeta del proyecto, crearemos un script llamado app.py donde escribiremos nuestro código python. En este script haremos una primera prueba con Streamlit con el siguiente código:
import streamlit as st
# escrevendo um título na página
st.title('Mi primera aplicación 🥳')
Para ver este código en acción, podemos abrir la terminal y escribir el siguiente comando:
streamlit run app.py
Después de unos segundos, debería abrirse una página mostrando el texto que escribimos, junto con un emoji:
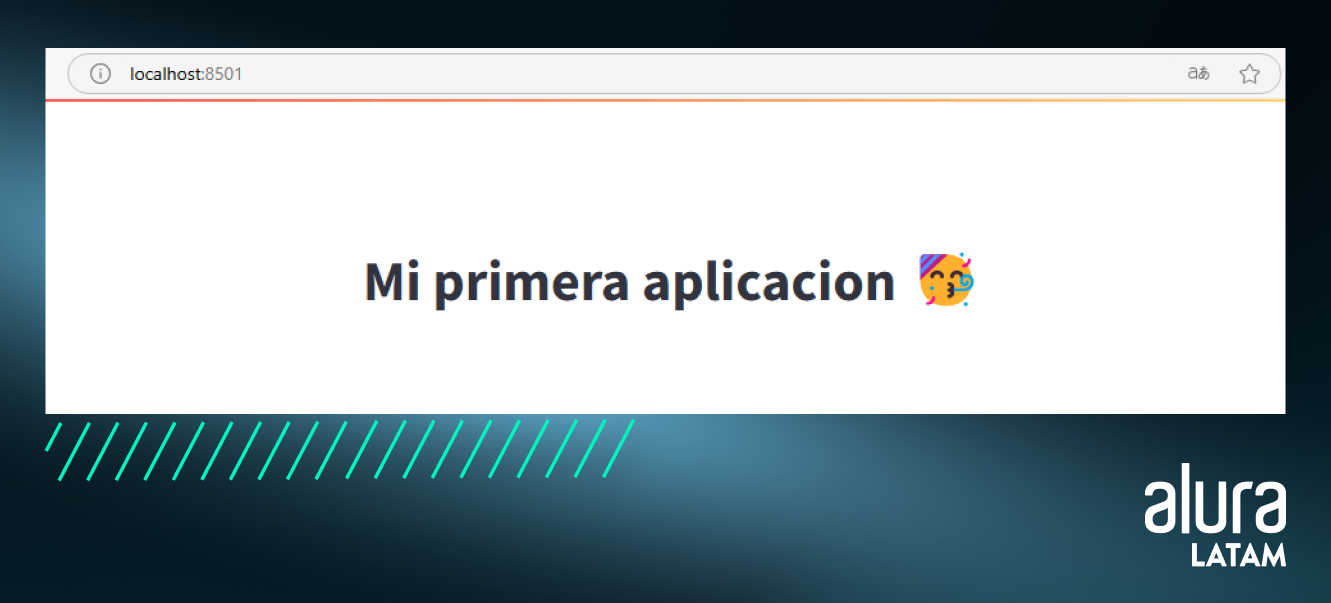
¡Entonces tenemos nuestra primera aplicación ejecutándose! Sin embargo, vemos que la url es localhost:8501, lo que indica que nuestra aplicación se esta ejecutando apenas localmente, o sea, aún no la tenemos disponible en la web para otras personas accesar.
Si volvemos al código y realizamos algún cambio, como eliminar el emoji del comando st.title, aparecerá la siguiente alerta en la esquina superior derecha de la página:

Esta alerta indica que se han realizado cambios en el archivo fuente de esta página. Junto a la alerta, se muestran dos opciones: Rerun(ejecutar nuevamente) y Always rerun(siempre ejecutar nuevamente). Cuando seleccionamos la opción “Rerun” nuestra página se recargará y se aplicarán los cambios realizados en el archivo. Si elegimos “Siempre volver a ejecutar” este proceso de recargar la página cada vez que se realice un cambio se volverá automático.
Ahora que entendemos un poco sobre cómo funciona Streamlit, podemos comenzar a desarrollar algo un poco más elaborado.
Creando tu primera aplicación de datos
Dado que el propósito de este artículo es explorar algunas de las características de Streamlit, no profundizaremos en los conceptos de ciencia de datos utilizados en el proyecto. Vamos a realizar una aplicación en la cual se presentará una tabla y una gráfica, por lo que habrá algunos filtros.
Para desarrollar el siguiente proyecto se utilizó una base de datos de productos de supermercados. Puedes acceder a él haciendo clic en el repositorio. Con el archivo descargado podemos guardarlo en nuestra carpeta de proyecto.
En el archivo app.py podemos eliminar el fragmento de código escrito anteriormente y realizar las siguientes importaciones:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import streamlit as st
Después de esto escribiremos el siguiente código:
# importando los datos
datos = pd.read_csv('stock.csv')
st.title('Analisis de stock\n')
st.write('En este proyecto vamos a analisar la cantidad de produtos en stock, por categoria, de una base de datos de produtos de supermercado')
En esta primera parte presentamos un título y un pequeño texto justo debajo del mismo. A medida que desarrollamos nuestro proyecto, es interesante monitorear el progreso visitando la página.
Ahora, comencemos a crear filtros para presentar el marco de datos en nuestra aplicación:
Para filtrar la categoría utilizamos un selectbox, donde ponemos como opciones cada una de las categorías y también la opción “Todas” para mostrar todas las categorías. Debajo de este selectbox, tenemos un segundo filtro que nos permite elegir el número de filas del dataframe que queremos presentar. Este filtro se define en la función mostrar_ctd_lineas() que debe agregarse al comienzo de nuestro código, justo después de importar las bibliotecas :
# función para seleccionar la cantidad de lineas del dataframe
def mostrar_ctd_lineas(dataframe):
ctd_lineas = st.sidebar.slider('Seleccione la cantidad de lineas que desea mostrar en la tabela', min_value = 1, max_value = len(dataframe), step = 1)
st.write(dataframe.head(ctd_lineas).style.format(subset = ['Valor'], formatter="{:.2f}"))
Esta función presenta un elemento llamado slider que es la barra de valores que permite elegir el número de filas deseadas para la visualización del dataframe, siendo el valor mínimo igual a 1 y el valor máximo igual al número máximo de filas según la categoría elegida previamente.
En este caso st.write , es responsable de presentar el dataframe según el número de filas elegidas. El método style.format que se encuentra dentro de write se utiliza para especificar que los valores en la columna "Valor" deben tener solo dos decimales después de la coma.
Continuando con los filtros, con el siguiente código:
# filtros para la tabla
checkbox_mostrar_tabla = st.sidebar.checkbox('Mostrar tabla')
if checkbox_mostrar_tabla:
st.sidebar.markdown('## Filtro para la tabla')
categorias = list(datos['Categoria'].unique())
categorias.append('Todas')
categoria = st.sidebar.selectbox('Seleccione la categoría para presentar en la tabla', options=categorias)
if categoria != 'Todas':
df_categoria = datos.query('Categoria == @categoria')
mostrar_ctd_lineas(df_categoria)
else:
mostrar_ctd_lineas(datos)
El primer paso que estamos dando en este código es crear una barra lateral utilizando el método sidebar de nuestra página. Nuestros filtros estarán ubicados en esta barra, para que los componentes queden ordenados de forma más organizada. Por lo tanto, cada vez que veamos el comando st.sidebar que precede a un componente, significa que ese componente estará ubicado en la barra lateral izquierda.
En esta barra lateral, primero agregamos una casilla de verificación "Mostrar tabla". Cuando el usuario seleccione esta opción aparecerán algunas alternativas de filtro y el dataframe se mostrará en el medio de la página.
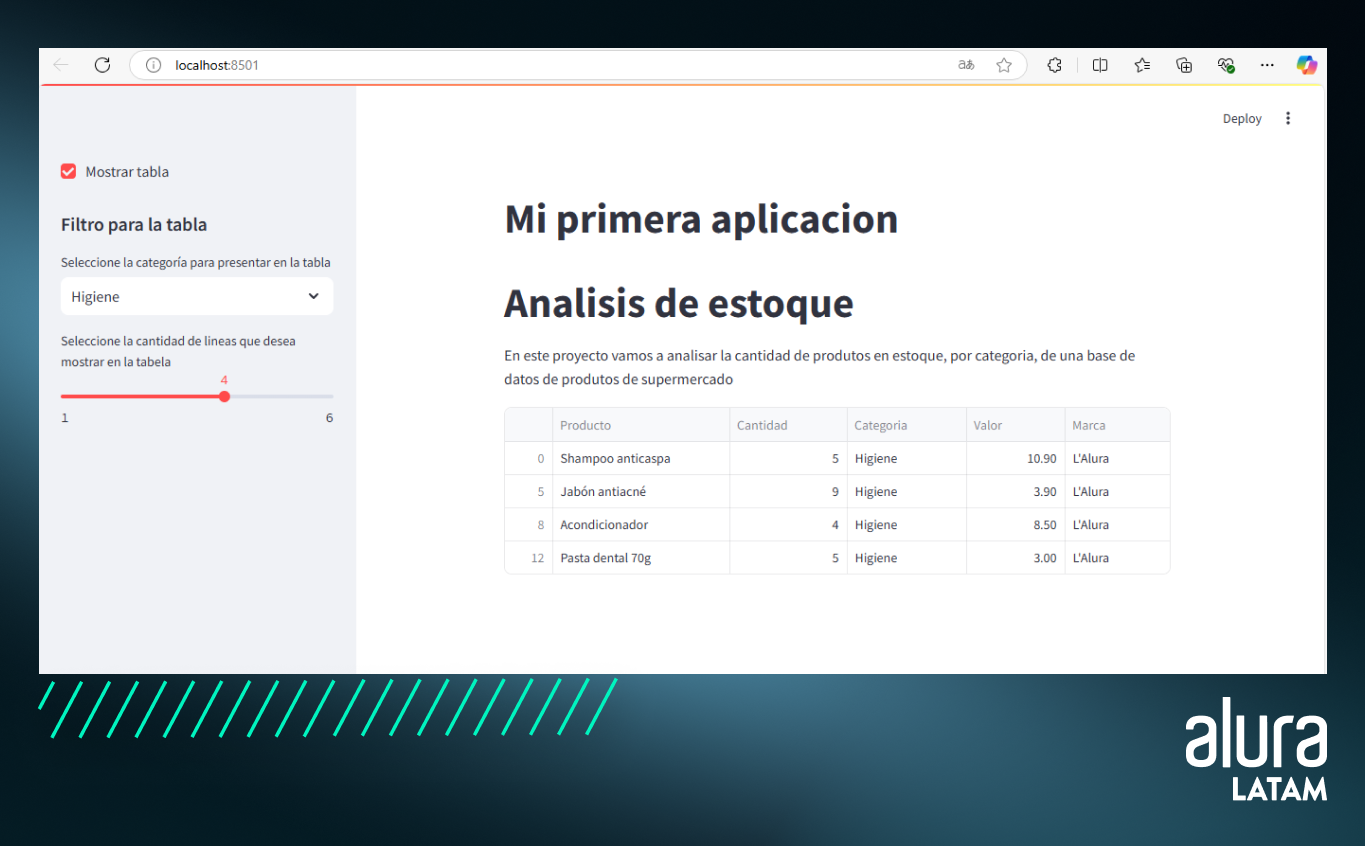
Para finalizar nuestro script, vamos a crear un filtro para presentar nuestro gráfico según categoría:
# filtro para el gráfico
st.sidebar.markdown('## Filtro para el gráfico')
categoria_grafico = st.sidebar.selectbox('Seleccione la categoria para presentar en el gráfico', options = datos['Categoria'].unique())
figura = plot_stock(datos, categoria_grafico)
st.pyplot(figura)
Con este código estamos creando un “subtítulo” a través de st.markdown y creando otro selectboxdonde la persona pueda seleccionar la categoría que desea visualizar en la gráfica. La opción seleccionada se almacena en la variable categoria_grafico y luego se crea este gráfico utilizando la función plot_stock(). Esta función utiliza las bibliotecas seaborn y matplotlib para crear el gráfico y devolver una figura, que se muestra en nuestra página a través de st.pyplot.
La función plot_stockdebe crearse al comienzo de nuestro script, justo después de la función mostrar_ctd_lineas. Puedes acceder al código de esta función haciendo clic aquí .
Una vez hecho esto, tendremos un filtro en nuestra página para seleccionar la categoría que queremos visualizar en la gráfica:

Así finalizamos nuestro proyecto. Pero antes de que podamos ponerlo en funcionamiento, necesitamos crear un repositorio y agregarlo a GitHub. ¿vamos a ello?
Creando un repositorio para nuestro proyecto
Para crear un repositorio necesitas tener una cuenta de GitHub.
Hay diferentes formas de subir un proyecto a GitHub. Sin embargo, como nuestro enfoque principal es Streamlit, optaremos por subir nuestro proyecto a Github de la forma más sencilla, que es directamente a través de la interfaz de ese sitio, sin entrar en demasiada profundidad en este tema.
Después de iniciar sesión en nuestra cuenta de GitHub, podemos acceder a la sección de repositorios y hacer clic para crear un nuevo repositorio. En esta pantalla debemos dar un nombre y seleccionar la casilla “Añadir un archivo README” para crear un archivo README. El nombre del repositorio será "Articulo_Streamlit_Alura".
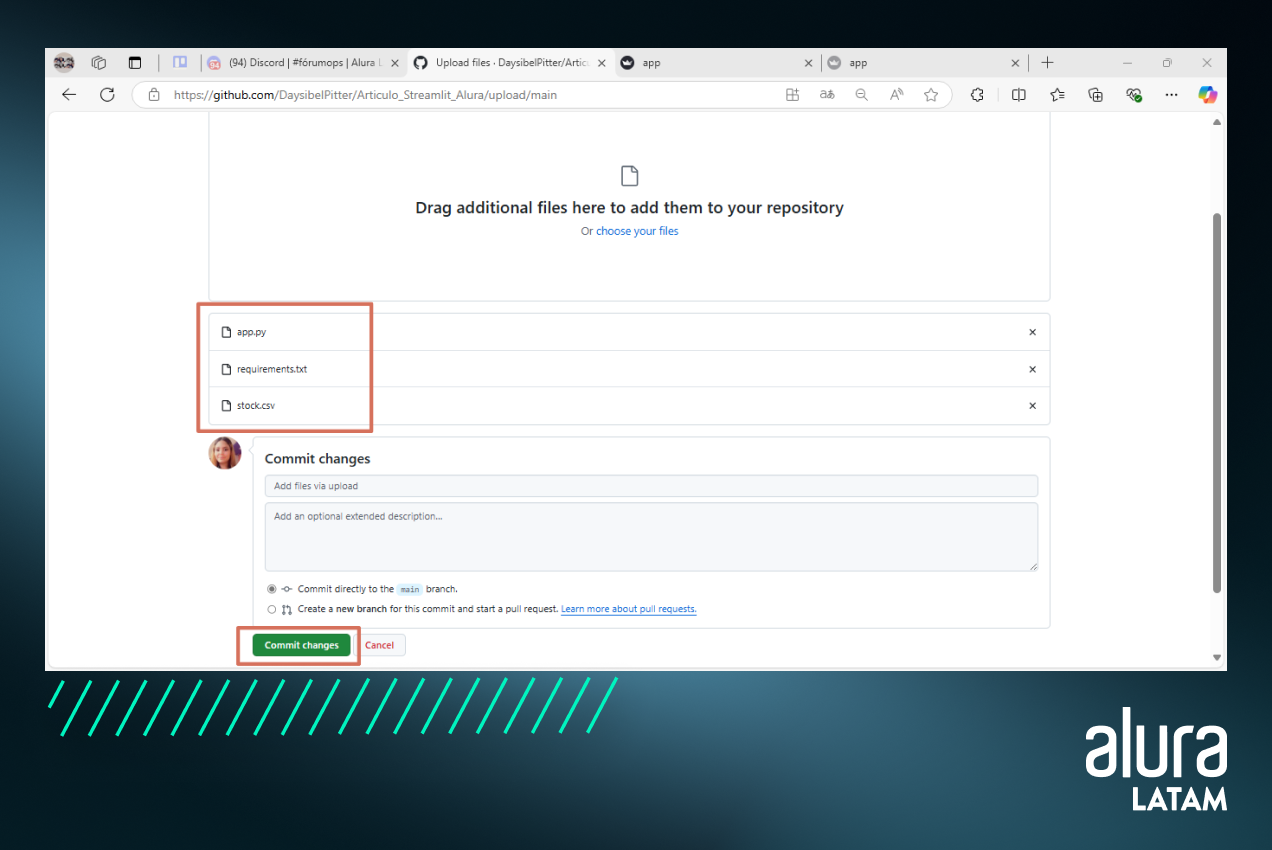
Para terminar de crear este repositorio, podemos hacer clic en la opción “Crear repositorio”. Con el repositorio creado, podemos agregar nuestros archivos al mismo. Para ello seleccionaremos la opción Añadir archivo > Subir archivos .
En la pantalla que nos aparece hacemos clic en “elige tus archivos”, accedemos a la carpeta que contiene los archivos de nuestro proyecto y seleccionamos aquellos que queremos subir al repositorio. Seleccionemos solo los archivos: app.py, stock.csv y requirements.txt y hagamos clic en "Confirmar cambios" para guardar los cambios.
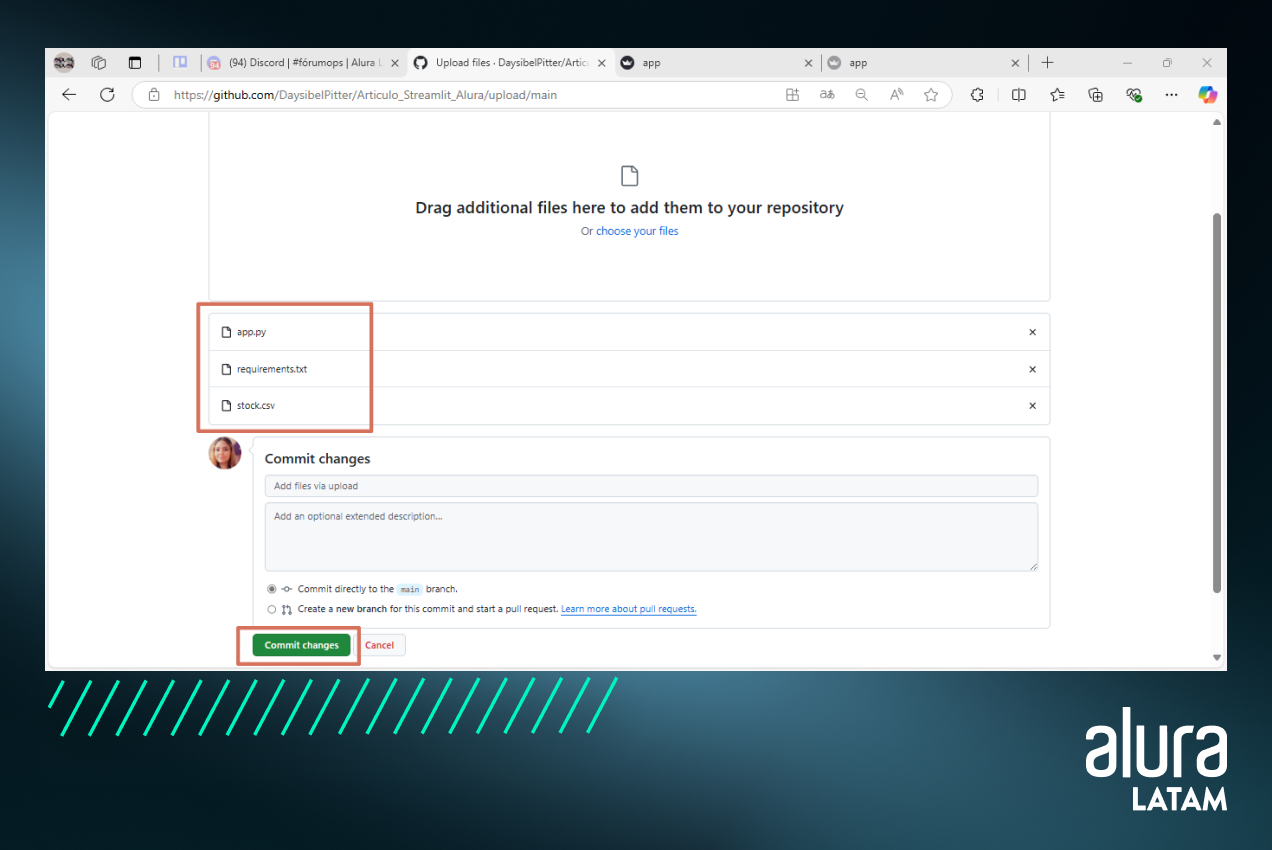
Ahora nuestro proyecto está listo para ser implementado. ¿Pasamos a la parte final?
Solicitud de acceso a la nube Streamlit
Para realizar la implementación, necesitamos solicitar acceso a las máquinas virtuales en la nube de Streamlit. Para hacer esta solicitud iremos a streamlit.
Clicamos en la opción Deploy on Community Cloud y luego en Comenzar. Eso nos llevará a una interfaz para registrarnos y tener acceso a las máquinas virtuales de esta herramienta.

También puedes acceder a ese enlace haciendo clic aquí .
En este enlace luego de elegir con cual email vas a crear tu cuenta o si decides entrar con github, luego de autenticarte como usuario, hay un formulario de registro donde debemos rellenar nuestro nombre, apellido y el email que utilizamos en GitHub aparte de otros datos que pidan. El último campo no es necesario rellenar. Con los campos rellenados, podemos hacer clic en “continuar”.

Una vez que se haya registrado, podemos continuar con la implementacion.
Desplegando nuestra aplicación
Después de recibir el correo electrónico confirmando nuestro registro, podemos iniciar sesión en el sitio web de Streamlit. En esta pantalla hay algunas opciones para iniciar sesión, podemos elegir la primera “Continuar con GitHub”.
La siguiente pantalla que aparece se titula Tus aplicaciones. Hay una opción resaltada en azul en la parte superior derecha de la pantalla, esta opción se llama "create app". Para añadir una nueva aplicación hacemos clic sobre ella.
Proporcionaremos los detalles de nuestro proyecto en GitHub en la página "Implementar una aplicación". En la primera parte del formulario debemos ingresar el repositorio donde se encuentra nuestro proyecto. Puedes hacerlo poniendo tu nombre de usuario de GitHub, una barra y el nombre del repositorio: github_username/Alura_Streamlit_Article , o puedes copiar el enlace del repositorio y pegarlo.
En la segunda parte del formulario, la Rama, no es necesario realizar ningún cambio ahora. En “Ruta del archivo principal” debemos poner el nombre del archivo que está en GitHub con el código principal de nuestra aplicación. En nuestro caso es app.py.

Una vez rellenado el formulario podemos hacer clic en “¡Implementar!” para comenzar a implementar nuestra aplicación. Este proceso puede tardar unos minutos en cargarse.

¡Ahora la aplicación está terminada y lista para ser compartida!
Tenga en cuenta que ya no tenemos esa URL con "localhost" escrito. Esto indica que la aplicación no solo se ejecuta localmente en nuestra máquina, sino en una máquina virtual, lo que permite que cualquiera pueda acceder a ella.
Puedes acceder a la aplicación creada en este artículo haciendo clic en este enlace .
¿Te gustó el contenido y quieres profundizar aún más en el mundo de la ciencia de datos? No olvides consultar nuestra Capacitación en Python para ciencia de datos , el curso de Visualización de datos : creación de gráficos con Matplotlib y el artículo Código de VisualStudio: instalación, atajos, complementos e integraciones .
Artículo adaptado y traducido por Daysibel Cotiz.

Millena Gená Pereira
Millena Gená es estudiante de Ciencias de la Computación. Actualmente, es Instructora de Datos aquí en Alura, trabajando principalmente en el área de Ingeniería de Datos. Ella siempre está buscando aprender algo nuevo sobre tecnología y le apasionan las nuevas aventuras. ¡Programar y ayudar a la gente son sus pasatiempos favoritos!
