


En cada campo de actividad existen varios problemas que se deben afrontar para lograr un objetivo, y en el área de Machine Learning no es diferente. En diferentes contextos podemos encontrar soluciones que surgen del mismo origen. A medida que exploramos el vasto universo del aprendizaje automático, hemos identificado una técnica fundamental para resolver muchos problemas: la clasificación. En este artículo abordaremos los principales problemas que resuelven los algoritmos de clasificación en Machine Learning, explorando cómo se pueden solucionar a través de tres categorías.
Clasificación
La clasificación es parte de un conjunto de técnicas que aprenden a partir de ejemplos, conocidas como aprendizaje supervisado . En este tipo de aprendizaje, sabemos cuáles son nuestros datos de entrada y también cuáles son las etiquetas correctas. Al entrenar el modelo basándose en resultados conocidos, es posible encontrar patrones en los datos, ya que el proceso implica ajustar los parámetros del modelo para minimizar el error entre las predicciones y los valores reales.
La clasificación es uno de los conceptos principales del aprendizaje automático, que implica categorizar los datos en función de sus características. En otras palabras, es el proceso de comprender , reconocer patrones y agrupar el conjunto de datos en categorías, con la ayuda de datos de entrenamiento precategorizados, de modo que sea posible determinar qué etiquetas se aplicarán a los datos no observados.
Imagina que estás preparando una lista de reproducción de canciones para una fiesta y necesitas elegir tres estilos musicales diferentes: rock, música electrónica y hip-hop. En este caso, es necesario conocer las características de cada uno de estos estilos para crear una lista de reproducción que guste a tus invitados.
Como alguien que disfruta de la música, ha escuchado estos estilos antes y puede identificar los patrones únicos en cada uno. Esta capacidad de identificar patrones es similar a la clasificación de datos en el aprendizaje automático, como categorizar el género musical de una canción en función de sus características. A continuación tenemos una representación gráfica de este ejemplo:
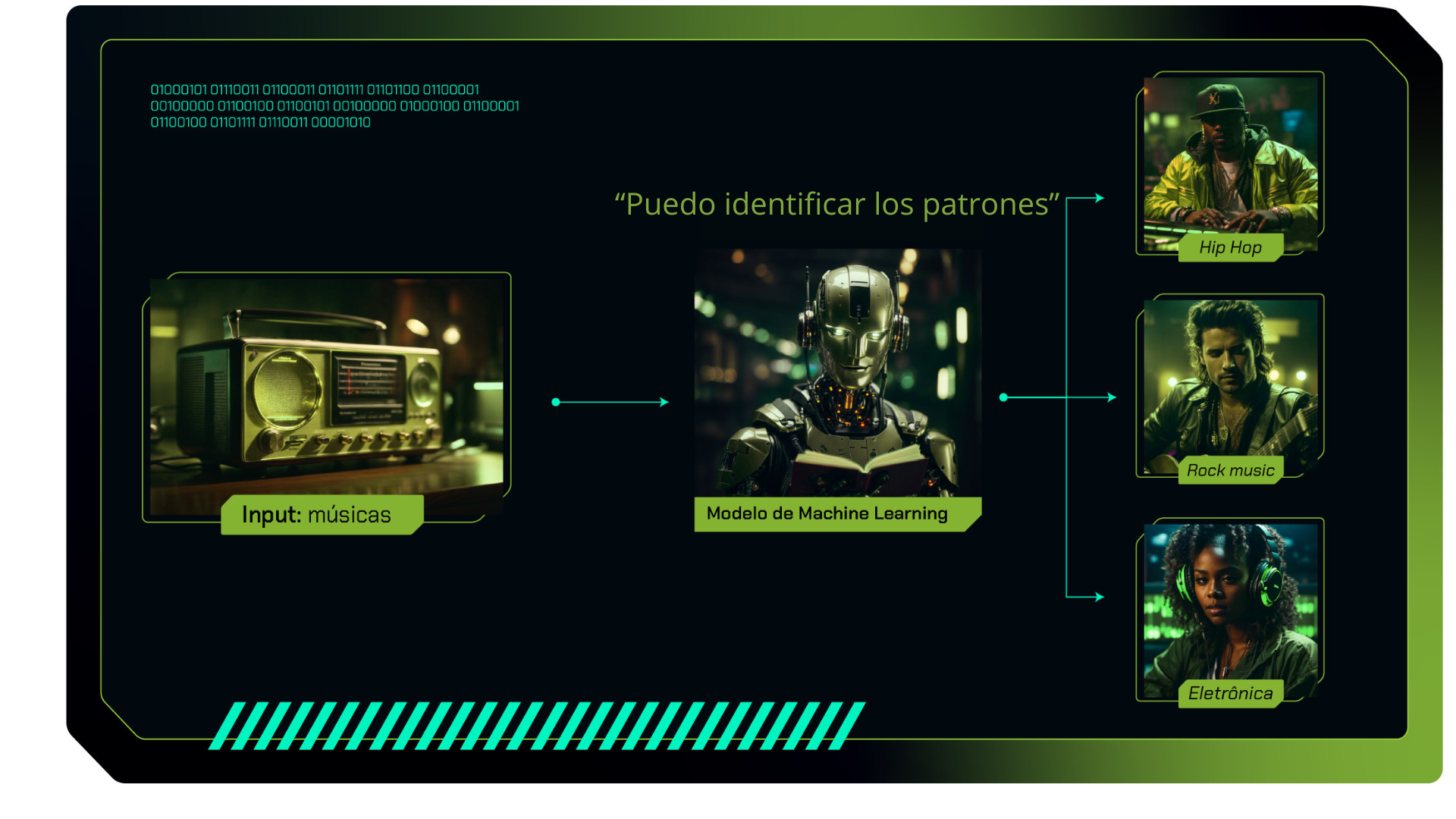
En la clasificación se aplica este mismo principio, ya que necesitamos saber de antemano cuáles son las respuestas correctas para poder conocer los atributos que caracterizan cada categoría. Esto nos permite responder nuevas preguntas sobre el tema.
Algoritmos de clasificación
Los algoritmos de clasificación son esenciales para categorizar datos, ya que a través de ellos podemos comprender y responder preguntas específicas en diferentes contextos y desafíos. A continuación se muestran algunos ejemplos:
- Naive Bayes: clasifica los datos según probabilidades condicionales.
- Redes Neuronales Artificiales: reconoce patrones y procesamiento del lenguaje natural inspirados en el funcionamiento del cerebro humano.
- Support Vector Machines (SVM): mapea datos en un espacio multidimensional y encuentra un hiperplano separador.
- Regresión logística: se utiliza principalmente en problemas de clasificación binaria para estimar la probabilidad de pertenecer a una de dos clases posibles.
- Árbol de decisión: clasifica nuevos datos siguiendo un conjunto de reglas.
- Random Forest: utiliza múltiples árboles de decisión juntos para mejorar la precisión de la clasificación y reducir el sobreajuste.
- Gradient Boosting: construye un modelo fuerte combinando varios modelos débiles de forma iterativa, minimizando los errores previos.
- K-Nearest Neighbors: realiza predicciones basadas en los k puntos de datos más cercanos al punto de consulta.
Categorías de clasificación
Los algoritmos de clasificación se pueden dividir en tres categorías principales : clasificación binaria, clasificación multiclase y clasificación multietiqueta. A continuación comprobaremos cada uno de ellos.
Clasificación binaria
En la clasificación binaria, la idea es clasificar los datos en solo dos categorías. Los datos se etiquetan en formato binario, por ejemplo: verdadero o falso, 0 o 1, spam o no spam, etc. Ejemplos de algoritmos de clasificación binaria son:
- Naive Bayes
- Redes neuronales artificiales
- Regresión logística
- Máquinas de vectores de soporte
- Árbol de decisiones
A continuación, tenemos un ejemplo de la clasificación de los animales, identificándolos como perros o gatos:
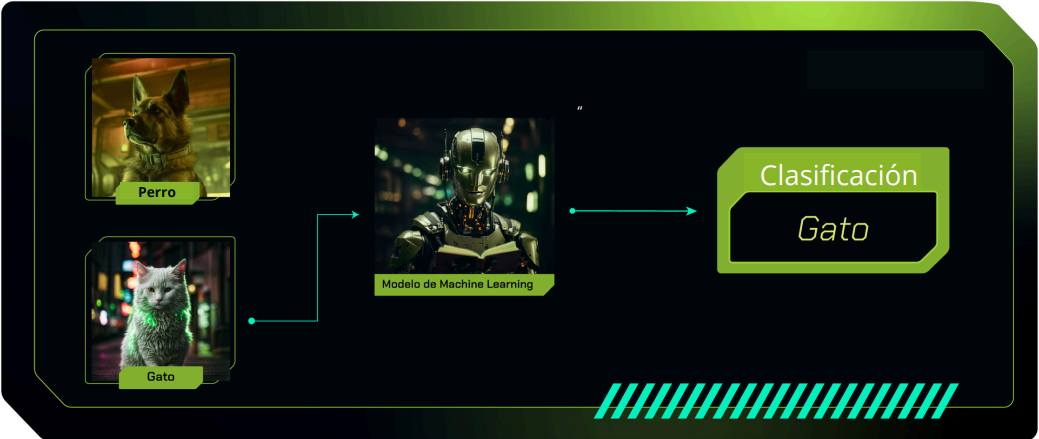
Clasificación multiclase
En la clasificación multiclase, los datos se clasifican en al menos dos categorías. La idea es descubrir a cuál de las dos o más categorías pertenecen los datos. La mayoría de los algoritmos utilizados en la clasificación binaria se pueden utilizar para la clasificación multiclase. Algunos algoritmos que forman parte de esta clasificación son:
- Naive Bayes
- Regresión logística
- Máquinas de vectores de soporte
- K-Nearest Neighbors
- Gradient Boosting
- Random Forest
A modo de ejemplo, podemos añadir una categoría más al ejemplo anterior, quedando así tres categorías: perro, gato y pájaro.
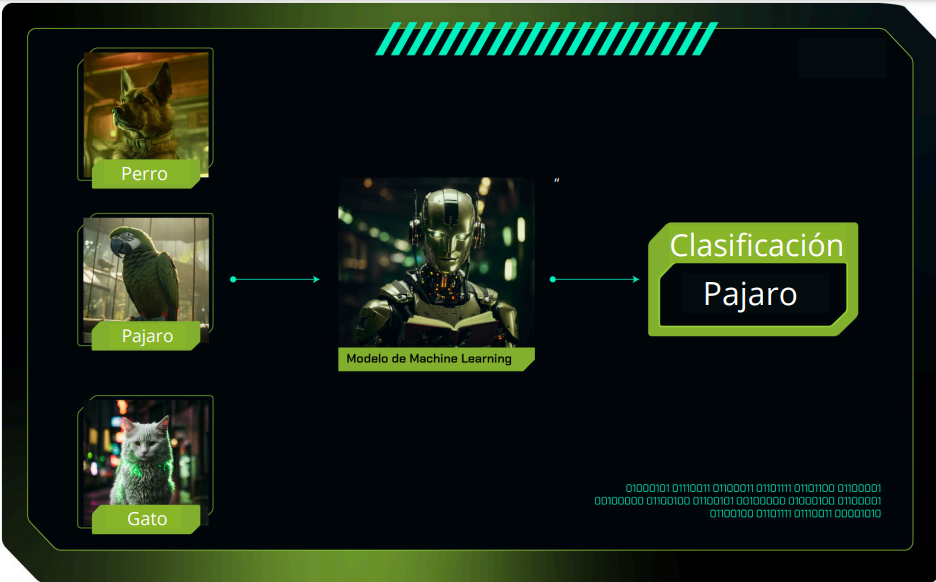
Clasificación multietiqueta
En la clasificación de etiquetas múltiples, los datos se clasifican en 0 o más categorías. En este caso, los mismos datos se pueden etiquetar en varias categorías. Para este tipo de clasificación, varios algoritmos estándar tienen su versión adaptada. Algunos ejemplos son:
- Árbol de decisión de múltiples etiquetas
- Gradient Boosting de múltiples etiquetas
- Random Forest de múltiples etiquetas
A modo de ejemplo, podemos tener una imagen que contenga varios animales, donde el algoritmo encontrará cada animal presente en la imagen:

Problemas resueltos mediante Clasificación
Mediante algoritmos de clasificación podemos resolver diferentes tipos de problemas. A continuación, veremos varios problemas que se resuelven mediante algoritmos de clasificación y comprenderemos por qué estos algoritmos se aplican a estos problemas particulares.
Detección de spam
La detección de spam es un problema común en las comunicaciones en línea, como correos electrónicos, comentarios de sitios web y redes sociales. Los algoritmos de clasificación son cruciales para filtrar mensajes no deseados basados en ciertas características, como palabras clave, patrones textuales, enlaces sospechosos y otra información relevante.
Algoritmos utilizados y sus características:
- Naive Bayes: son rápidos de entrenar y pueden manejar bien datos de alta dimensión, como las representaciones de texto utilizadas en la detección de spam.
- Redes neuronales artificiales: permiten capturar representaciones semánticas complejas de palabras y oraciones, haciéndolas adecuadas para el procesamiento del lenguaje natural.
- Máquinas de vectores de soporte (SVM): son efectivas para reglas simples y heurísticas, lo que las hace adecuadas para escenarios donde hay patrones de spam conocidos.
Predicción de Churn
Predecir la tasa de Churn, o cancelación de clientes, es importante para las empresas que buscan retener a sus clientes. Los algoritmos de clasificación pueden analizar datos de clientes y comportamientos de compra para clasificar a los clientes en categorías como “propenso a abandonar” o “no propenso a abandonar”, lo que permite estrategias de retención proactivas.
Algoritmos utilizados y sus características:
- Regresión logística y árboles de decisión: son interpretables y pueden brindar información sobre qué características tienen la mayor influencia en la predicción de abandono.
- Random Forest: es muy versátil, ofrece una combinación de varios árboles de decisión y maneja bien datos complejos, características mixtas e interacciones potenciales entre variables.
Detección de fraude
La detección de fraudes es un tema crucial en muchas industrias, especialmente en las finanzas y el comercio electrónico. Los algoritmos de clasificación pueden analizar patrones de comportamiento y transacciones para identificar actividades sospechosas, minimizando pérdidas y manteniendo la seguridad. Pueden clasificar las transacciones como “fraude” o “no fraude” según características como la ubicación, el monto, el tipo de transacción y el comportamiento del cliente.
Algoritmos utilizados y sus características:
- Regresión logística: puede ser útil en los casos donde las relaciones entre las variables son más simples y la interpretabilidad es importante.
- Árboles de decisión: son excelentes para trabajar con datos desequilibrados y pueden capturar relaciones no lineales entre características. Esto es importante para identificar patrones sutiles de fraude.
Análisis de crédito
El análisis de crédito es esencial para las instituciones financieras al momento de evaluar la probabilidad de que un cliente pague o no sus deudas. Los algoritmos de puntuación evalúan el riesgo crediticio de las personas según el historial de pagos, los ingresos y la información financiera para clasificar a los solicitantes en categorías como "riesgo bajo", "riesgo medio" y "riesgo alto". Esto ayuda a las instituciones a tomar decisiones informadas sobre la concesión y los límites del crédito.
Algoritmos utilizados y sus características:
- Regresión logística: esta es una opción común para problemas de clasificación binaria, como decidir si un solicitante tiene un riesgo crediticio alto o bajo.
- Árboles de decisión: permite tratar atributos mixtos (numéricos y categóricos) frecuentemente presentes en los datos de análisis de crédito.
Otros problemas
Además de los problemas destacados anteriormente, los algoritmos de aprendizaje automático también se aplican con éxito en varias otras áreas:
- Clasificación de documentos o textos : se utiliza para categorizar automáticamente documentos y textos, haciendo más eficiente la organización y búsqueda de información.
- Análisis de sentimientos : es la capacidad de determinar sentimientos en textos, como positivos, negativos o neutrales, lo cual es útil para analizar opiniones y comentarios.
- Clasificación de imágenes : se utiliza para identificar objetos y patrones en imágenes, siendo útil en áreas como la medicina, la industria y la automatización.
Conclusión
Los algoritmos de clasificación son fundamentales en el campo del Machine Learning, permitiendo la categorización precisa de los datos en función de sus diferentes aspectos. La clasificación es una técnica versátil que se puede utilizar para resolver problemas en una variedad de áreas, como negocios y marketing, salud, medios y entretenimiento, finanzas, procesamiento del lenguaje natural, entre otros. Para conseguir resultados efectivos es fundamental elegir los algoritmos adecuados para cada tipo de problema, teniendo en cuenta sus características específicas.
Entonces, ¿te gustó la lectura? Aquí en Alura tenemos muchos otros contenidos para ayudarte a estructurar tu conocimiento sobre Machine Learning. ¿Quieres sumergirte en la tecnología? ¡Ven a estudiar con nosotros!
Marcelo Cruz
Soy Licenciado en Informática por la UNIR. Actualmente soy Instructor en la escuela de Datos. Disfruto mucho aprender y compartir conocimientos. Apasionado por Python y los datos.
Artículo adaptado y traducido por Daysibel Cotiz.
