

 ¿Alguna vez has pensado en cómo sería trabajar con datos sin la ayuda de la estadística? Imagina lo complicado que sería intentar extraer información o tomar decisiones solo observando una gran cantidad de datos, sin herramientas para organizar, interpretar y validar esa información.
¿Alguna vez has pensado en cómo sería trabajar con datos sin la ayuda de la estadística? Imagina lo complicado que sería intentar extraer información o tomar decisiones solo observando una gran cantidad de datos, sin herramientas para organizar, interpretar y validar esa información.
En la Ciencia de Datos, la estadística es lo que nos permite transformar los datos en conocimiento práctico, guiando desde las etapas iniciales de análisis hasta la construcción y validación de modelos.
El problema es que, muchas veces, la estadística puede parecer intimidante o complicada, especialmente para quienes están empezando en el área de Datos. ¡Pero no tiene por qué ser así!
La buena noticia es que, cuando se entiende y aplica correctamente, la estadística puede simplificar la toma de decisiones y resolver problemas complejos con eficiencia.
En este artículo, exploraremos cómo la estadística desempeña un papel crucial en la Ciencia de Datos y cómo puedes utilizarla de manera práctica y accesible.
Vamos a ver cómo los Científicos de Datos utilizan métodos estadísticos para resolver problemas del mundo real, cuáles son los análisis más comunes y qué herramientas estadísticas se usan con mayor frecuencia.
¿Tienes curiosidad? Acompáñame y descubre cómo la estadística puede transformar la manera en que trabajas con datos.
¿Cuál es la relación entre la Ciencia de Datos y la Estadística?
Imagina que trabajas en una tienda online y necesitas descubrir por qué las ventas de un producto específico están disminuyendo. Tienes acceso a una gran cantidad de datos, como el número de visitas a la página del producto, reseñas, historial de compras e incluso información demográfica de los clientes. Ahora, la pregunta es: ¿cómo transformar todos esos datos en una solución práctica?
Para entender por qué las ventas están bajando, primero debes explorar los datos y tratar de encontrar patrones. Puedes empezar aplicando técnicas estadísticas para analizar la distribución de los datos, calcular el promedio de las reseñas de los clientes o entender cómo variables como la edad y la región afectan las ventas.
¿Será que los clientes más jóvenes están comprando menos? ¿Será que las reseñas negativas están afectando las ventas? Afortunadamente, la estadística proporciona herramientas para responder estas y otras preguntas de forma clara y objetiva.
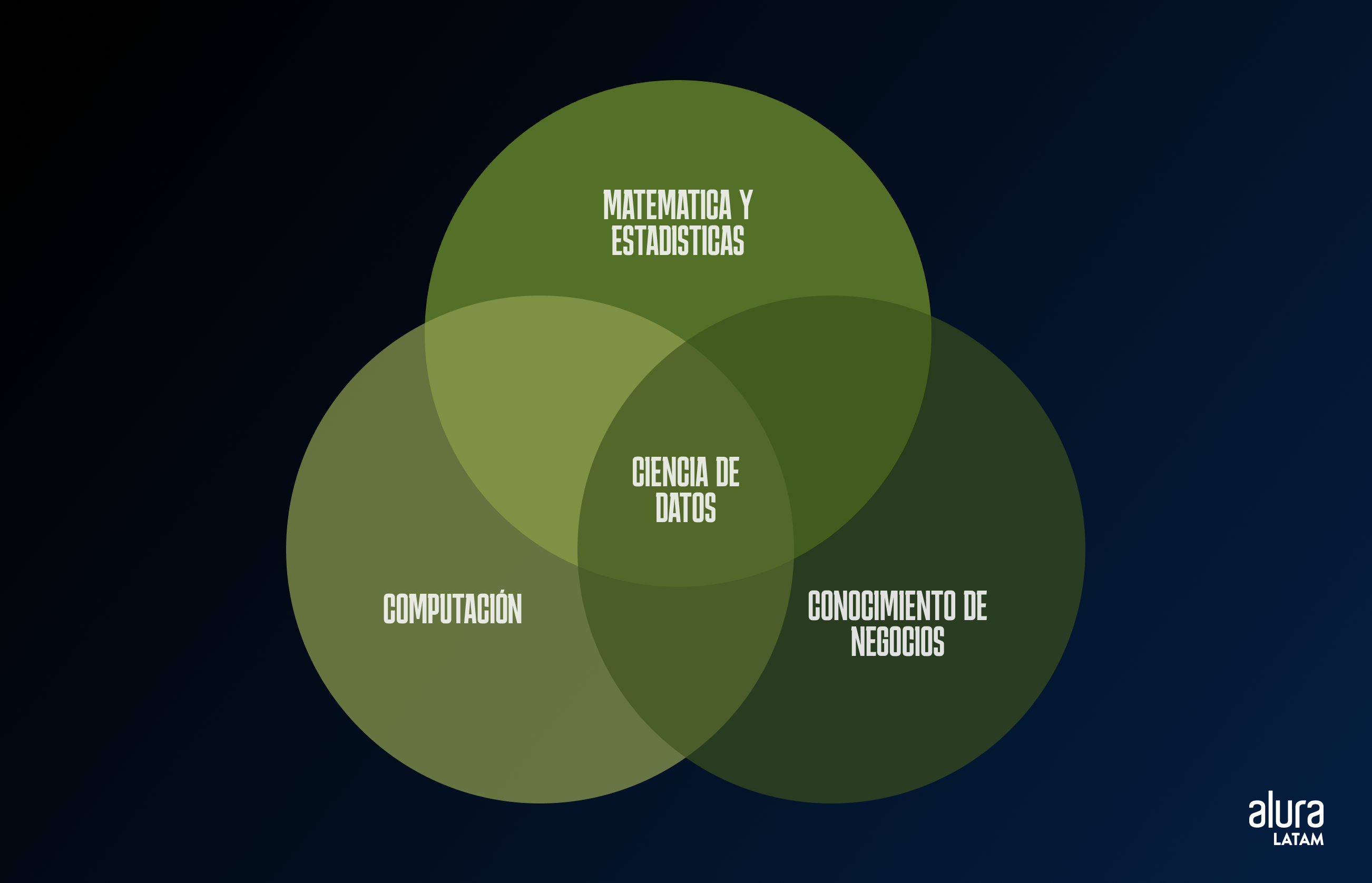
La estadística ya es poderosa, pero en la Ciencia de Datos se vuelve aún más eficaz al integrarse con otras dos áreas esenciales: la computación y el conocimiento de negocio.
Esta combinación permite que los Científicos de Datos no solo realicen análisis precisos, sino que también escalen estos análisis y los apliquen de manera práctica en escenarios reales, generando valor para las organizaciones.
Abajo, tenemos el famoso Diagrama de Venn que ilustra las intersecciones entre estas tres áreas.
La estadística proporciona la base para el análisis de datos, mientras que la computación facilita el procesamiento y la automatización de esos análisis a gran escala. Por su parte, el conocimiento de negocio garantiza que los insights extraídos sean relevantes y aplicables al contexto específico de la empresa.
¡Genial! Ya entendemos cómo la estadística es parte de la ciencia de datos, pero ¿cómo la aplican los científicos de datos en la práctica en su vida diaria?
¿Cómo aplican la estadística los Científicos de Datos en su día a día?
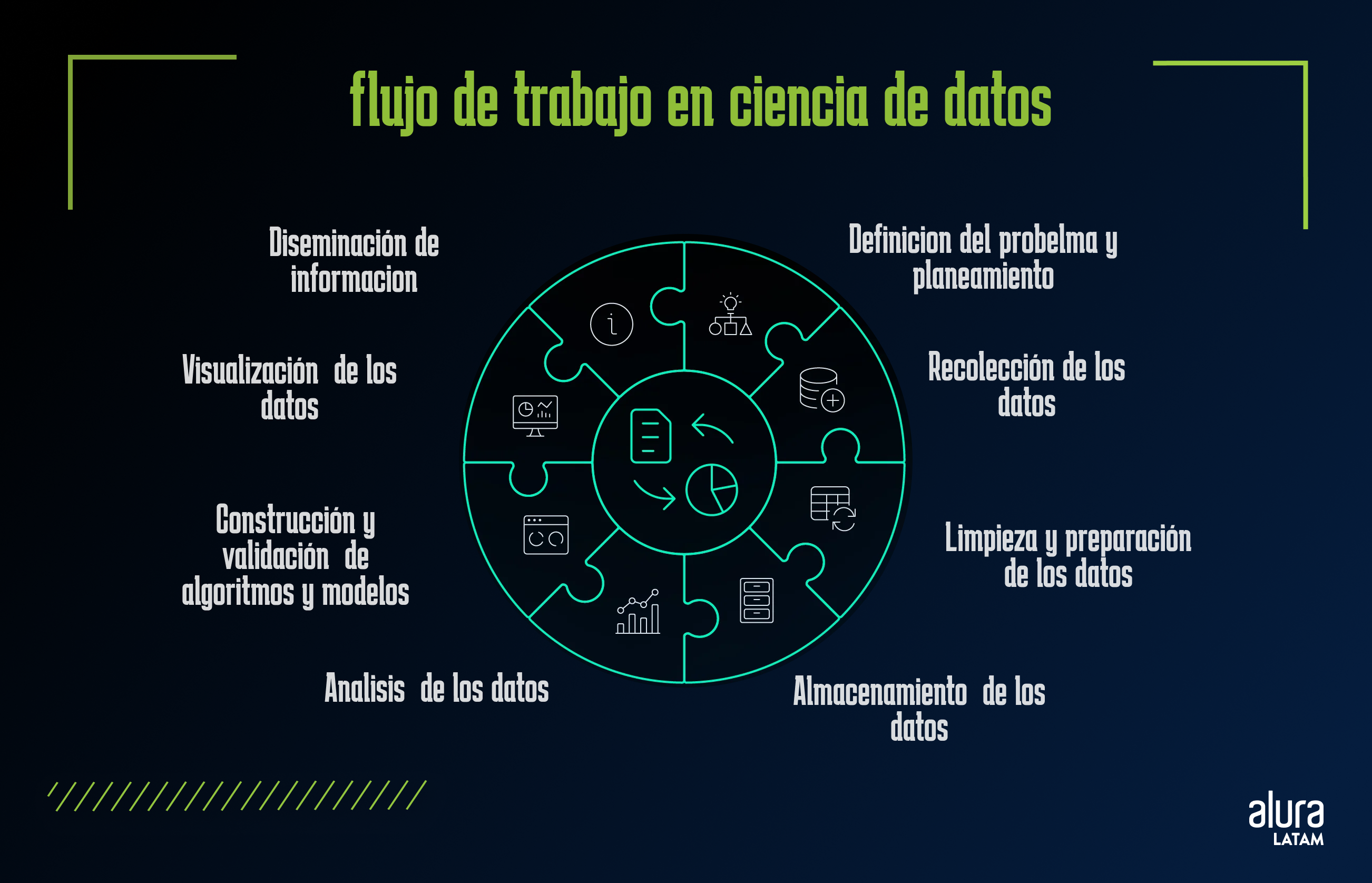
Para entender cómo los Científicos de Datos utilizan la estadística, exploremos el flujo de trabajo en el área de Datos.
Cuando vamos a desarrollar un proyecto, el proceso comienza con la definición clara del problema que se desea resolver.
Luego, se elabora una planificación cuidadosa para la recolección de datos.
Después de la recolección, esos datos pasan por un proceso de limpieza y preparación, que es esencial para garantizar que los análisis que siguen sean de calidad.
Durante esta fase, la generación de visualizaciones gráficas puede ayudar a identificar valores atípicos, datos faltantes o inconsistencias, haciendo el proceso de limpieza más eficaz.
Con los datos listos, el Científico de Datos puede aplicar métodos estadísticos y algoritmos de Machine Learning para extraer insights, identificar patrones y realizar predicciones.
Una vez validados los resultados, pueden visualizarse de forma clara e intuitiva.
Esta visualización no solo facilita la interpretación de los datos, sino que también hace que la comunicación de los hallazgos sea más accesible y comprensible para diferentes públicos, incluidos gestores y equipos no técnicos.
Este ciclo iterativo y continuo es crucial, ya que permite constantes refinamientos en los análisis y en los modelos desarrollados, siempre con el objetivo de fundamentar decisiones en datos confiables y precisos.
Así, la estadística no es solo una herramienta, sino una aliada indispensable en la búsqueda de comprensión e innovación en un mundo lleno de información.
Descripción de los datos
Imagina que acabas de recolectar datos sobre las compras de una tienda en línea. Observas que, entre varias informaciones, tienes datos como la edad de los clientes y el valor que gastan.
¿Cómo podrías entender mejor este conjunto de datos? La respuesta está en la descripción de los datos. A través de estadísticas descriptivas, como el promedio y la desviación estándar, puedes crear un retrato claro de tu público.
Por ejemplo, si la edad promedio de sus clientes es de 30 años y la mayoría gasta alrededor de 150 $, esto puede ayudar a la empresa a orientar sus estrategias de marketing de manera más efectiva.
Test de hipótesis
Imagina que estás trabajando en un proyecto para mejorar la tasa de conversión de un sitio web. Crees que cambiar el color del botón "Comprar" puede aumentar las ventas.
Para probar esto, formulas dos hipótesis: la hipótesis nula (H0), que dice que el cambio no tendrá efecto, y la hipótesis alternativa (H1), que afirma que el cambio tendrá un impacto positivo.
Después de recopilar datos sobre las tasas de conversión antes y después del cambio, se utilizan técnicas estadísticas para verificar si la diferencia observada es significativa. Las pruebas de hipótesis le permiten tomar decisiones informadas basadas en datos, minimizando el riesgo de sacar conclusiones erróneas.
Análisis de varianza (ANOVA)
¿Qué pasaría si necesitaras comparar la eficacia de tres medicamentos diferentes para tratar una enfermedad específica?
Cada medicamento se administra a un grupo distinto de pacientes y la eficacia se evalúa mediante una puntuación de mejora clínica.
Supongamos que el medicamento "A" tiene una mejora promedio de 80 puntos, el medicamento "B" tiene 75 puntos y el medicamento "C" tiene 85 puntos.
Mediante el análisis de varianza (ANOVA), puede determinar si las diferencias en las mejoras medias entre grupos de pacientes que reciben cada medicamento son estadísticamente significativas.
ANOVA prueba la hipótesis nula de que todas las medias son iguales, es decir que los medicamentos sean igualmente eficaces.
Si el resultado de ANOVA rechaza esta hipótesis nula, concluimos que al menos uno de los medicamentos tiene una eficacia significativamente diferente a los demás.
Esta técnica se puede utilizar para comparar los promedios de dos o más grupos en varias áreas, además de la salud.
Prueba A/B
Supongamos que trabajas para una empresa de comercio electrónico y deseas saber qué diseño de página genera más ventas.
Decides probar dos versiones de la misma página: versión A (original) y versión B (con algunos cambios).
Después de dirigir la mitad del tráfico a cada versión, verás cuál genera más ventas.
Después de un período, analiza los datos y comprueba qué diseño funcionó mejor. Las pruebas A/B son esenciales para optimizar productos y estrategias, permitiéndole implementar cambios que realmente han demostrado ser mejores.
Modelos predictivos
Considere un escenario en el que deseas prever las ventas de una tienda para el próximo mes.
Usando datos históricos de ventas, estacionales y otras variables, puedes construir un modelo predictivo.
Imagina que tu modelo indica que, basado en tendencias anteriores, puedes esperar un aumento del 15 % en las ventas.
Con esta información, la tienda puede ajustar su inventario y sus estrategias de marketing para satisfacer la demanda prevista, evitando pérdidas y maximizando ganancias.
Evaluación de modelos
Después de crear un modelo predictivo, ¿cómo saber si realmente está funcionando bien?
Supongamos que has creado un modelo de regresión para prever el precio de casas basado en características como tamaño y ubicación.
Para evaluar su rendimiento, puedes utilizar el error cuadrático medio (MSE), que mide el promedio de las diferencias entre los precios reales y los previstos. Si el MSE es de 25.000 $, esto indica que el modelo presenta un error de este valor en relación con el valor previsto, sea hacia arriba o hacia abajo.
Además, existe el coeficiente de determinación (R²), que muestra la proporción de la variación en los precios que tu modelo es capaz de explicar.
Por ejemplo, un R² de 0,85 significa que el modelo captura el 85 % de la variación en los precios.
Estos insights ayudan a identificar la efectividad de tu modelo y la necesidad de ajustes, como incluir más variables o probar diferentes algoritmos para mejorar las predicciones.
Storytelling con datos
Piensa en un Científico de Datos presentando los resultados de un análisis de ventas. ¿Qué sería más atractivo para el público objetivo: mostrar solo números en tablas o crear gráficos que cuenten una historia? Yo definitivamente voto por la segunda opción, ¿y tú?
Al mostrar una visualización que enseña, por ejemplo, cómo las ventas aumentaron tras una campaña de marketing específica, es posible transmitir el mensaje de manera clara e impactante.
El storytelling con datos coloca los datos en un contexto real, ayudando al equipo a entender qué funcionó y qué puede mejorarse, facilitando la toma de decisiones más precisas.
Bueno, estas son algunas de las formas de aplicar estadística en la Ciencia de Datos. Increíble, ¿no? Pero, ¿qué herramientas podemos usar para realizar estas tareas?
En el área de Ciencia de Datos, los lenguajes de programación más populares son Python y R.
A continuación, exploraremos herramientas disponibles en ambos lenguajes.

Herramientas estadísticas más usadas en Ciencia de Datos
En Ciencia de Datos, tanto Python como R son lenguajes de programación ampliamente utilizados, y ambos tienen varias bibliotecas y paquetes que facilitan la aplicación de técnicas estadísticas.
Estas herramientas son fundamentales para realizar análisis detallados y transformar datos crudos en información valiosa. A continuación, te presento las bibliotecas y paquetes más utilizados en ambos lenguajes.
Python
Pandas: es una biblioteca esencial para la manipulación y análisis de datos en Python. Ofrece estructuras de datos como DataFrames y Series, que permiten trabajar con datos tabulares de manera eficiente e intuitiva. Es ideal para tareas como limpieza de datos, transformaciones, obtención de estadísticas descriptivas y agregación de información.
Matplotlib: es la base para la creación de gráficos en Python, permite visualizar distribuciones de datos, tendencias y patrones estadísticos a través de gráficos como histogramas, gráficos de dispersión, líneas de tendencia, entre otros.
Seaborn: basada en Matplotlib, proporciona una interfaz de alto nivel para la creación de gráficos de forma más intuitiva y elegante. Ofrece recursos avanzados para visualizaciones de correlación, distribución y variación, ideales para análisis estadísticos más detallados.
NumPy: es fundamental para operaciones estadísticas que involucran cálculos con arrays y matrices. Soporta funciones estadísticas básicas como media, mediana, desviación estándar y varianza, además de ser la base para operaciones más complejas en otras bibliotecas.
SciPy: es utilizada para tareas estadísticas más avanzadas como intervalos de confianza, pruebas de hipótesis y análisis de regresión.
Statsmodels: utilizada para modelado estadístico avanzado, permite la construcción de modelos de regresión lineal y análisis de series temporales.
Scikit-learn: conocida principalmente por sus funcionalidades de Machine Learning, esta biblioteca también proporciona herramientas estadísticas como regresión y métricas de validación de modelos. También incluye métodos para validación cruzada, esencial para evaluar la eficacia de modelos.
R
- dplyr: es un paquete de R ampliamente utilizado para manipulación y análisis de datos, que facilita la aplicación de técnicas estadísticas mediante una sintaxis intuitiva y eficiente. Permite realizar operaciones como filtrado, selección de variables, creación de nuevas columnas y resumen de datos de manera rápida y clara.
- ggplot2: es una de las herramientas más poderosas y flexibles para visualización de datos en R. Permite a los usuarios crear gráficos complejos y estéticamente agradables con relativa facilidad. Ideal para explorar datos o presentar resultados analíticos, ggplot2 ofrece una amplia gama de tipos de gráficos, como boxplots, histogramas y gráficos de dispersión, que pueden personalizarse y combinarse fácilmente para comunicar insights de forma eficaz.
- stats: este paquete proporciona una amplia gama de funciones y herramientas para realizar análisis estadísticos, incluidos modelos de regresión, pruebas de hipótesis, análisis de varianza (ANOVA), entre otros.
- caret: es una herramienta unificada para el entrenamiento y evaluación de modelos de Machine Learning. Simplifica el proceso de creación de modelos predictivos, ofreciendo funciones para preprocesamiento de datos, selección de características, ajuste de hiperparámetros y evaluación de modelos.
¡Bastante interesante, ¿no?! Independientemente de si el lenguaje es Python o R, el dominio de estas bibliotecas y paquetes permite a los Científicos de Datos resolver una variedad de problemas, desde análisis descriptivos y validación de hipótesis hasta modelado predictivo.
Conclusión
Si te estás aventurando en la Ciencia de Datos, la estadística caminará de la mano contigo. Ofrece herramientas indispensables para interpretar datos, validar hipótesis y garantizar que las soluciones desarrolladas sean robustas y confiables.
La estadística siempre ayudará a transformar datos en insights significativos, asegurando que las decisiones tomadas se basen en evidencia sólida.
¿Qué te parece aprender estadística de forma práctica y aplicada? Aquí en Alura, tenemos una formacion increíble esperándote: enfocada en el lenguaje Python.
¡Ven a estudiar con nosotros y potencia tus habilidades! 🚀

Valquíria Alencar
Doctorado en Biotecnología y posdoctorado realizado en la Universidad Federal del ABC. Actualmente se desempeña como instructora en la escuela de Ciencia de Datos, donde desarrolla proyectos y cursos que abarcan preprocesamiento y análisis exploratorio de datos, visualización de datos en Python, aplicación de inteligencia artificial generativa, además de la implementación y optimización de modelos de aprendizaje automático. También es una de las autoras del libro Séries Temporais com Prophet, publicado por la Editora Casa do Code.
