

Revisa en este artículo:
- ¿Qué es el Machine Learning?
- Como funciona el Machine Learning?
- História: ¿cómo surgió el Machine Learning?
- ¿Para qué se utilizan los modelos de Machine Learning?
- Diferencia entre Machine Learning e Inteligencia Artificial
- Tipos de aprendizaje automático
- Algoritmos comunes de ML
- Ventajas y desventajas
- Carreras en Machine Learning
- El futuro del Machine Learning
- Cursos en el área de ML
- Más información sobre el Machine Learning
- Preguntas más frecuentes
- Conclusión
- Créditos
De acuerdo con la pesquisa de McKinsey, 46% de las empresas ya usaron el Machine Learning en sus negócios.
El Machine Learning es uno de los desarrollos más importantes de la inteligencia artificial (IA), que ha demostrado ser fundamental en las estrategias empresariales para aumentar la productividad.
No en vano, los profesionales que se especializan en modelos de Machine Learning (ML) están ganando cada vez más protagonismo en el mercado laboral.
Todo esto es suficiente para mostrar la necesidad de prepararse para trabajar con esta tecnología, ¿no es así?
Con eso en mente, el propósito de este artículo es explorar qué es el Machine Learning, especialmente qué es y donde se aplica esta tecnología.
¿Qué es el Machine Learning?
El Machine Learning es una rama de la Inteligencia Artificial que se centra en crear sistemas que puedan aprender de los datos.
En lugar de estar programados con reglas específicas para realizar una tarea directamente, estos sistemas se entrenan utilizando datos y algoritmos que les permiten mejorar su rendimiento para lograr su objetivo.
En otras palabras, el aprendizaje automático permite a las computadoras aprender de los datos, sin tener que programar explícitamente esta tarea.
Esto contribuye a la anticipación de escenarios en diversas aplicaciones que van desde la predicción meteorológica hasta la detección de fraudes en las transacciones bancarias.
Puede aplicar el aprendizaje automático en muchas áreas diferentes, como la previsión de ventas, la detección de fraudes, la recomendación de productos, el diagnóstico médico, etc.
Esto es gracias a la gran cantidad de datos que almacenamos hoy en día. Estos datos pueden ser de varios tipos, como números, textos, imágenes, vídeos y audios.
Es decir, básicamente, cualquier información que podamos almacenar en el ordenador puede servir para entrenar un algoritmo de aprendizaje automático.
Live Café Punto Tech - ¿Cómo dar tus primeros pasos en el mundo de Data Science?
¿Cómo funciona el Machine Learning?
Dependiendo de la técnica de aprendizaje automático, la aplicación del entrenamiento de un modelo es diferente. Pero pudimos sintetizar este proceso utilizando características que están presentes en todos los métodos de aprendizaje automático.
En términos generales, el trabajo del aprendizaje automático es tratar de detectar varios patrones que están presentes en un conjunto determinado de datos.
Para ello, los datos iniciales se envían a un algoritmo de aprendizaje automático, que entrena este modelo para que aprenda a identificar patrones en los datos.
Después del entrenamiento, es posible probar, evaluar, optimizar y poner en producción el modelo de Machine Learning, dependiendo del objetivo de la aplicación del modelo.
El resultado de un modelo de aprendizaje automático depende del tipo de algoritmo que utilice. Si se trata de un algoritmo de clasificación, cuyo objetivo es identificar a qué categoría pertenece una muestra determinada, el modelo devolverá la clase predicha para esa muestra.
Si se trata de un algoritmo de regresión, que busca predecir un valor numérico en función de las características de la muestra, el modelo devolverá un valor numérico.
O, si se trata de un algoritmo de agrupamiento, que tiene como objetivo agrupar muestras similares, el modelo devolverá los grupos formados a partir de las características de las muestras.
Historia: ¿cómo surgió el Machine Learning?
Arthur Samuel es el programador pionero en el campo del aprendizaje automático, principalmente porque desarrolló el primer programa de aprendizaje automático del mundo, además de haber acuñado, por primera vez, el término "Machine Learning".
Desafortunadamente, entre los años 70 y 80 se produjo el "invierno de la IA", un período en el que la gente mostró poco interés en investigar e invertir en el campo del ML o la IA.
El fin de esta era estuvo marcado por muchos avances que implicaron el desarrollo de algoritmos expertos, como NETtalk, en 1985, una Red Neuronal Artificial que aprendió a pronunciar textos escritos en inglés, asociando palabras con su fonética.
O un caso más famoso, Deep Blue, un algoritmo capaz de jugar al ajedrez y que, en 1997, venció a Garry Kasparov, campeón de este deporte en ese momento.
El inicio de la comercialización de máquinas virtuales por parte de Amazon con Elastic Compute Cloud (Amazon EC2) marcó la década de los 2000, lo que facilitó la implementación de modelos de ML con mayor necesidad de potencia de procesamiento.
Esto hizo posible que los estudios que involucran datos y modelos más complejos fueran ampliamente avanzados a lo que tenemos actualmente.
¿Para qué se utilizan los modelos de Machine Learning?
Como ya sabes, es posible aplicar el Machine Learning en diversas situaciones y áreas de actividad. Los que más destacan son los siguientes:
- Pronóstico y análisis;
- Reconocimiento de patrones;
- Personalización de la experiencia;
- Clasificación y categorización;
- Optimización de procesos;
- Diagnóstico Médico;
- Seguridad Cibernética; y
- Prevención de mantenimiento.
1) Previsión y análisis
En sectores como el financiero y el empresarial, destaca la aplicación del machine learning para la predicción y el análisis. Es decir, los algoritmos pueden analizar los historiales del mercado para predecir tendencias futuras.
Por ejemplo, entrenar un modelo de aprendizaje automático con datos anteriores puede predecir con precisión las fluctuaciones del precio de las acciones, lo que ayuda a los inversores a tomar decisiones sobre la compra o venta de activos.
2) Reconocimiento de patrones
Una aplicación interesante con el reconocimiento de patrones es en la visión artificial, como en los sistemas de reconocimiento facial.
A través de algoritmos de aprendizaje automático, estos sistemas pueden identificar patrones únicos en la estructura facial, lo que permite una autenticación segura.
En este caso, las aplicaciones prácticas incluyen el desbloqueo de teléfonos inteligentes y sistemas de seguridad que utilizan la biometría facial para la autorización de acceso.
Además del ejemplo anterior, es posible utilizar esta aplicación en diversas situaciones, desde el reconocimiento de voz hasta la detección de fraudes en transacciones financieras.
3) Personalización de la experiencia
Las plataformas de streaming, como Netflix, aplican el aprendizaje automático para personalizar la experiencia de los usuarios.
En este caso, los algoritmos de aprendizaje automático analizan el historial de visualización, los comportamientos y las preferencias de los usuarios. A partir de esta información, recomienda contenidos personalizados.
El resultado de esto es una experiencia mucho más atractiva, y probablemente mucho más satisfactoria, basada en las sugerencias.
4) Clasificación y categorización
En el área de los correos electrónicos, el aprendizaje automático se utiliza para clasificar automáticamente los mensajes como spam o legítimos.
Mediante el uso de algoritmos que identifican patrones en los textos y comportamientos asociados con correos electrónicos no deseados, los sistemas de clasificación pueden separar los mensajes de manera eficiente.
Esto garantiza que los usuarios solo recibirán correo relevante en sus bandejas de entrada. La propuesta de valor es ahorrar tiempo y aumentar la eficacia de la comunicación electrónica.
5) Optimización de procesos
En la optimización de procesos, el machine learning se aplica en diversos sectores, como la logística y la cadena de suministro.
Los objetivos, en estos casos, son predecir las demandas futuras, reducir los inventarios innecesarios y mejorar el flujo de producción.
Por ejemplo, las empresas de reparto utilizan algoritmos de aprendizaje automático para optimizar las rutas de entrega, minimizando el tiempo y los costes de transporte, lo que se traduce en una mayor eficiencia operativa.
6) Diagnóstico médico
En la atención médica, los algoritmos se entrenan con grandes conjuntos de datos clínicos, como pruebas de imágenes y datos de laboratorio, para ayudar a los profesionales médicos a identificar enfermedades.
Un ejemplo es el uso de redes neuronales convolucionales (CNN) en radiología para analizar imágenes de tomografías computarizadas e identificar anomalías, como tumores o fracturas, con alta precisión, lo que permite intervenciones más rápidas y precisas.
7) Ciberseguridad
En ciberseguridad, el aprendizaje automático se utiliza para detectar patrones de comportamiento sospechosos en redes y sistemas.
Por ejemplo, los algoritmos de detección de anomalías pueden identificar actividades inusuales, como accesos no autorizados o intentos de intrusión, protegiendo así contra los ciberataques.
Estos sistemas aprenden de los datos históricos y en tiempo real para anticipar y responder a las amenazas de seguridad, al tiempo que mantienen la integridad de los sistemas y datos corporativos.
8) Prevención de mantenimiento
En la industria, la aplicación del machine learning en la prevención del mantenimiento se destaca como una herramienta valiosa para evitar fallos inesperados de los equipos.
Para ello, los algoritmos se entrenan con datos de rendimiento y condiciones de funcionamiento para predecir cuándo puede fallar una máquina.
Al monitorear constantemente variables como la temperatura, la vibración y la eficiencia, los sistemas de aprendizaje automático pueden anticipar la necesidad de mantenimiento, lo que permite intervenciones programadas antes de que ocurran fallas.
Esto no solo reduce los costos asociados con las paradas no programadas, sino que también aumenta la vida útil del equipo y mejora la eficiencia operativa.
Descubre el poder del Machine Learning
Diferencia entre Machine Learning e Inteligencia Artificial
Muchas personas confunden los términos "Machine Learning" e "Inteligencia Artificial". Sin embargo, es importante saber que no son conceptos idénticos.
IA es el término más completo, que comprende cualquier aplicación o máquina que imite la inteligencia humana, como GPT-3 y GPT-4 y ChatGPT, Midjourney y Generative AI Studio.
Articulo Primeros pasos en Inteligencia Artificial (IA)
Por lo tanto, el Machine Learning es un subconjunto de la IA. Es como si se tratara de uno de los tipos (o especies) de inteligencia artificial.
En general, se trata de máquinas o programas que, después de recibir entrenamiento con los datos existentes, pueden identificar patrones, hacer predicciones o realizar tareas frente a datos no publicados.
Esta técnica consiste en convertir los datos y la experiencia en conocimiento, generalmente expresado a través de modelos matemáticos.
Un ejemplo de esto es un sistema de Machine Learning que, a través del entrenamiento en imágenes, ha desarrollado la capacidad de analizar la resonancia magnética para reconocer patrones tumorales, a menudo superando la capacidad de los especialistas.
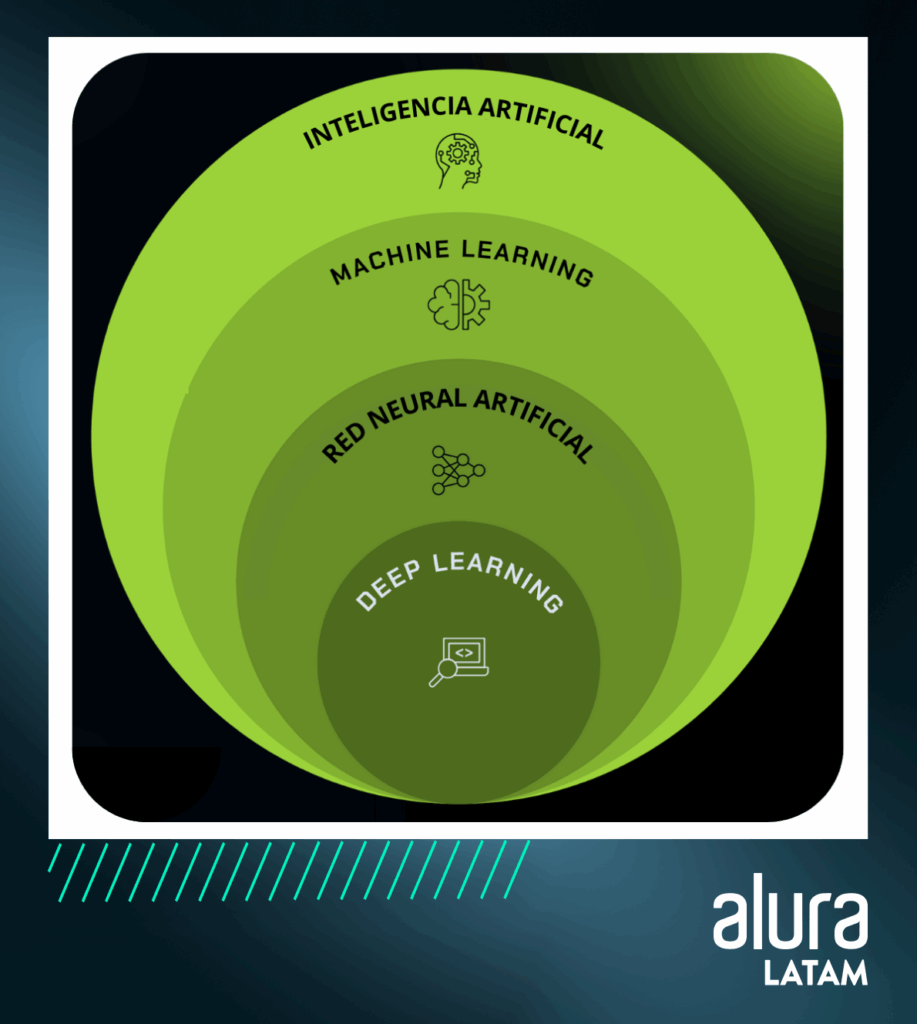
A partir del Diagrama de Venn, es posible observar la relación entre la Inteligencia Artificial y el Machine Learning: el ML es una subárea del campo de la Inteligencia Artificial.
Aunque el nombre de "Inteligencia Artificial" sugiere que siempre se tendrá un algoritmo de Machine Learning, en este campo también hay aplicaciones que no utilizan ML.
Un subconjunto en cuestión se llama GOFAI (Good Old-Fashioned Artificial Intelligence).
En él, los sistemas de IA se basan en reglas y lógica programada manualmente por los desarrolladores, sin depender de la capacidad de aprender de los datos.
Un ejemplo clásico de GOFAI son los chatbots simples que responden preguntas proporcionando respuestas preprogramadas, que se utilizan ampliamente en el servicio al cliente.
Deep Learning, Redes Neurales y el Machine Learning
El Machine Learning, el Deep Learning y las Redes Neurales son conceptos que se relacionan entre sí, cada uno desempeñando un papel específico en el campo de la Inteligencia Artificial.
El aprendizaje automático es el campo más amplio de los tres, ya que representa un conjunto de algoritmos que permiten a un sistema aprender patrones de los datos y tomar decisiones basadas en ese aprendizaje.
Existe una diversidad de algoritmos de ML y algunos de ellos se encuentran dentro del campo del Deep Learning.
Las Redes Neuronales se caracterizan por ser una técnica de aprendizaje dentro del dominio más amplio del Machine Learning.
Es una estructura computacional compuesta por nodos computacionales (las "neuronas"), que se organizan en capas. Estas capas incluyen una capa de entrada, una capa de salida y capas potencialmente ocultas.
Cuando la red neuronal tiene más capas más allá de la entrada y la salida (es decir, más de tres o más capas), se clasifica como "profunda". En este caso, es un ejemplo de Deep Learning.
Redes Neuronales: Deep Learning con PyTorch
El Deep Learning es un enfoque avanzado dentro del campo del Machine Learning que destaca por el uso de Redes Neuronales Artificiales Profundas.
La estructura más estratificada permite a la red modelar patrones complejos y realizar tareas sofisticadas de procesamiento de información, comúnmente simulando el funcionamiento del cerebro humano.
En comparación con los algoritmos de aprendizaje profundo, una red neuronal artificial común puede resolver solo problemas de aprendizaje más simples.
Tipos de aprendizaje automático
Actualmente, existen cuatro tipos de aprendizaje automático:
Aprendizaje supervisado; Aprendizaje no supervisado; Aprendizaje semi-supervisado; y Aprendizaje por refuerzo.
1) Aprendizaje supervisado
El aprendizaje supervisado es un enfoque en el aprendizaje automático en el que la máquina se entrena utilizando ejemplos de entrada y sus salidas correspondientes.
En otras palabras, se enseña al modelo a asociar los datos de entrada con resultados conocidos. Por ejemplo, al construir un sistema para el reconocimiento de flores, el aprendizaje supervisado implicaría alimentar al algoritmo con imágenes de flores ya etiquetadas con sus especies correspondientes.
El modelo aprende a identificar patrones y características asociadas con cada especie durante el entrenamiento. Más tarde, cuando se le presenta una nueva imagen de flor, el modelo puede predecir las especies en función de los patrones aprendidos.
2) Aprendizaje no supervisado
En el aprendizaje no supervisado, los modelos exploran datos sin etiquetar para identificar patrones y estructuras ocultos.
Una técnica común en este tipo de aprendizaje es el Clustering, que consiste en agrupar datos similares.
Por ejemplo, dado un conjunto de datos sobre las interacciones en las redes sociales, el aprendizaje no supervisado podría revelar agrupaciones naturales de personas que comparten intereses similares.
Este análisis permite descubrir comunidades o grupos de usuarios en función de patrones de comportamiento, lo que contribuye a una comprensión más profunda de las dinámicas sociales en la plataforma.
3) Aprendizaje semi-supervisado
El aprendizaje semisupervisado es una categoría que se encuentra en la intersección del aprendizaje supervisado y no supervisado. Surgió de la dificultad de establecer etiquetas manualmente a partir de un gran volumen de datos en contextos del mundo real.
Desde esta perspectiva, el aprendizaje semisupervisado se aplica a conjuntos de datos en los que solo una parte de los ejemplos están etiquetados, mientras que otra parte permanece sin etiquetar.
Con estos datos, el modelo de aprendizaje tiene acceso a información parcial sobre el resultado deseado, lo que le permite aprender patrones y relaciones a partir de los datos etiquetados disponibles.
Al mismo tiempo, el modelo utiliza los datos no etiquetados para extrapolar y generalizar estos patrones a instancias no observadas.
Por ejemplo, una empresa puede tener un gran conjunto de datos sobre sus clientes, como el historial de compras, el comportamiento de navegación del sitio web, etc.
Sin embargo, solo puede etiquetar una pequeña parte de estos datos, como si la persona ha realizado una compra o no.
El aprendizaje semisupervisado se puede utilizar para identificar patrones en los datos no etiquetados en función de la información aprendida de los datos etiquetados. Esto puede ayudar a la empresa a identificar clientes potenciales y mejorar sus estrategias de marketing.
4) Aprendizaje por refuerzo
El aprendizaje por refuerzo es una técnica de aprendizaje automático basada en la retroalimentación en la que un agente aprende a comportarse en un entorno realizando acciones y observando los resultados.
Cada acción exitosa da como resultado una retroalimentación positiva para el agente, mientras que las acciones inapropiadas reciben retroalimentación negativa o penalizaciones.
A diferencia del aprendizaje supervisado, en el aprendizaje por refuerzo, el agente aprende automáticamente a través de la retroalimentación, sin depender de datos etiquetados.
Podemos traer una aplicación para el desarrollo de juegos. En un juego, un agente (la persona que está jugando) necesita tomar una serie de decisiones (acciones) para lograr un objetivo (ganar el juego).
El agente no tiene instrucciones explícitas sobre cómo jugar el juego, pero recibe comentarios (recompensas) basados en el resultado de sus acciones.
Un ejemplo famoso de aprendizaje por refuerzo en juegos es el programa AlphaGo de DeepMind, que fue el primer programa de inteligencia artificial en derrotar a un campeón mundial humano en el juego de Go y tenía como algoritmo de aprendizaje automático un modelo de aprendizaje por refuerzo.
Algoritmos comunes de ML
Existe una gran diversidad de algoritmos de Machine Learning que cubren los más diversos problemas y objetivos. Entre los más comunes podemos mencionar:
Regresión lineal
La regresión lineal es uno de los algoritmos de Machine Learning más sencillos y comunes. Trabaja con conceptos matemáticos y estadísticos para predecir un valor, por lo que se utiliza habitualmente en problemas de Regresión con Aprendizaje Supervisado.
La estrategia principal de este modelo es identificar la relación matemática y lineal entre un valor de salida y los valores de entrada. La regresión lineal encuentra la línea que mejor representa la relación entre las variables.
La representación que mejor demuestre esta relación será una línea que minimice las distancias entre ésta y todos los puntos de intersección entre los valores de las variables.
Por ejemplo, si estamos prediciendo los precios de la vivienda, la regresión lineal aprendería la relación entre las características de la casa, como el número de habitaciones y sus precios, encontrando la mejor línea para hacer predicciones.
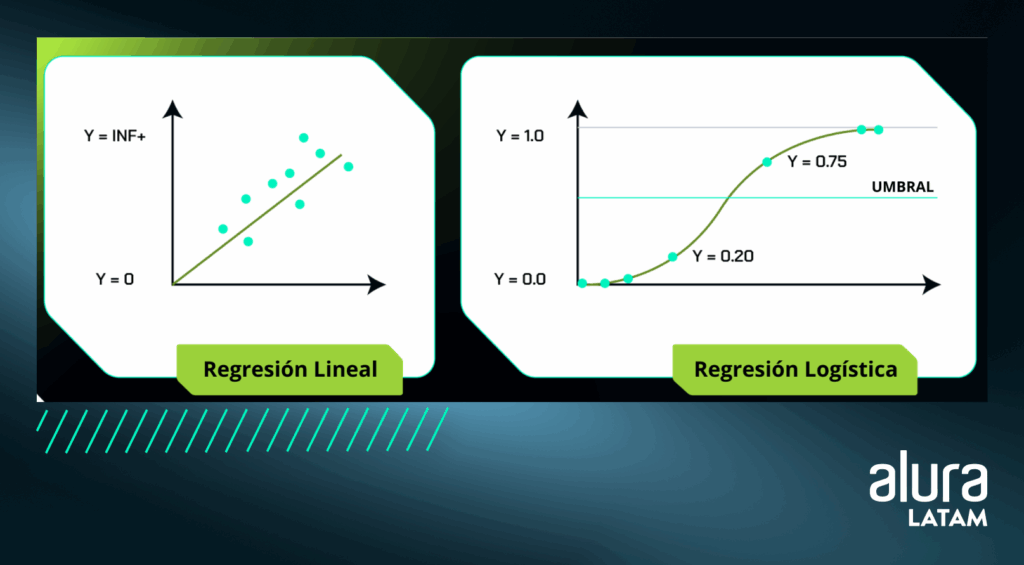
Desafortunadamente, lo que hace que la regresión lineal sea un algoritmo simple también la hace muy limitada, porque para que el modelo funcione correctamente, debe haber una relación lineal entre las variables de entrada y la variable de salida etiquetada.
En contraste con esta desventaja, en la Regresión Lineal es posible observar la representación gráfica de la relación lineal entre las variables. Puedes ver más ejemplos en el artículo Desvendando la regresión lineal.
Regresión logística
A pesar de que hay "Regresión" en su nombre y se puede aplicar a problemas de Regresión, la Regresión Logística se usa comúnmente en problemas de Clasificación Binaria.
Esto se logra porque la regresión logística proporciona valores probabilísticos entre 0 y 1, que pueden representar la probabilidad de que una muestra pertenezca a una clase específica.
La palabra "Logística" en el nombre del algoritmo, se refiere a la función logística (también conocida como Sigmoide) que se aplica a la combinación lineal de las características del conjunto de datos.
A diferencia de la regresión lineal, que tiene una línea que puede alcanzar varios valores, la función logística tiene forma de "S" y transforma los valores en una escala de 0 a 1.
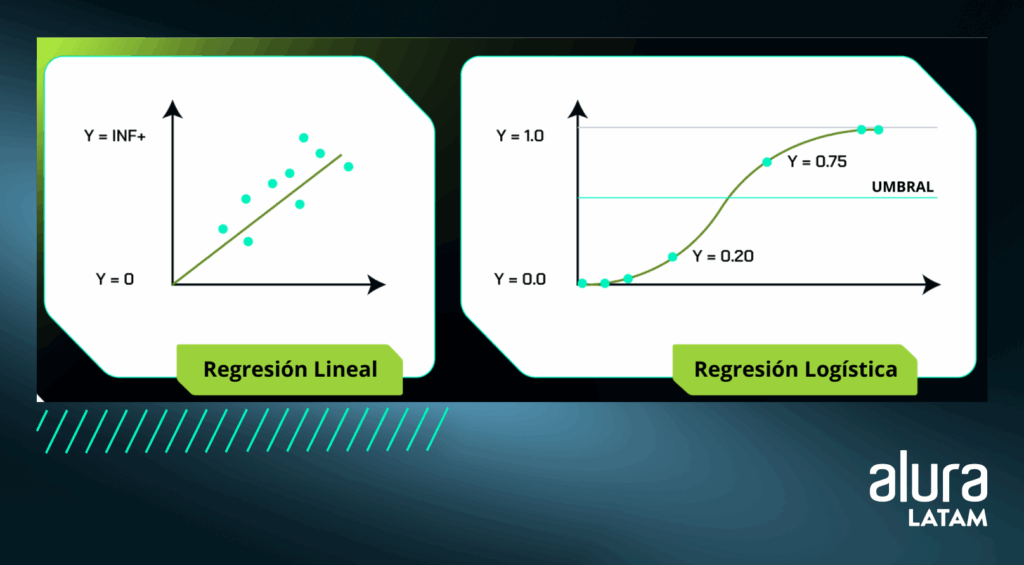
Para decidir la probabilidad de que una muestra pertenezca a una categoría, el modelo utiliza el umbral que determina el límite entre las clases.
Este valor suele especificarse como 0,5 y tiene un gran impacto en las decisiones: si la probabilidad Y está por encima del umbral, la instancia se asigna a la clase positiva; de lo contrario, a la clase negativa.
Árboles de decisión
El árbol de decisión, empleado en el aprendizaje supervisado para la clasificación y la regresión, es una estructura jerárquica compuesta por nodos de decisión y nodos hoja.
Durante el entrenamiento, el algoritmo comienza con un nodo raíz que representa todo el conjunto de datos, dividiéndolo de forma recursiva en función de las variables de entrada hasta que cada subconjunto contiene solo una clase o un valor de salida.
La estructura final muestra una raíz conectada a los nodos de decisión, que representan las opciones basadas en las variables de entrada, y a los nodos hoja, que indican los resultados finales. Como podemos ver en el esquema simplificado de esta estructura:
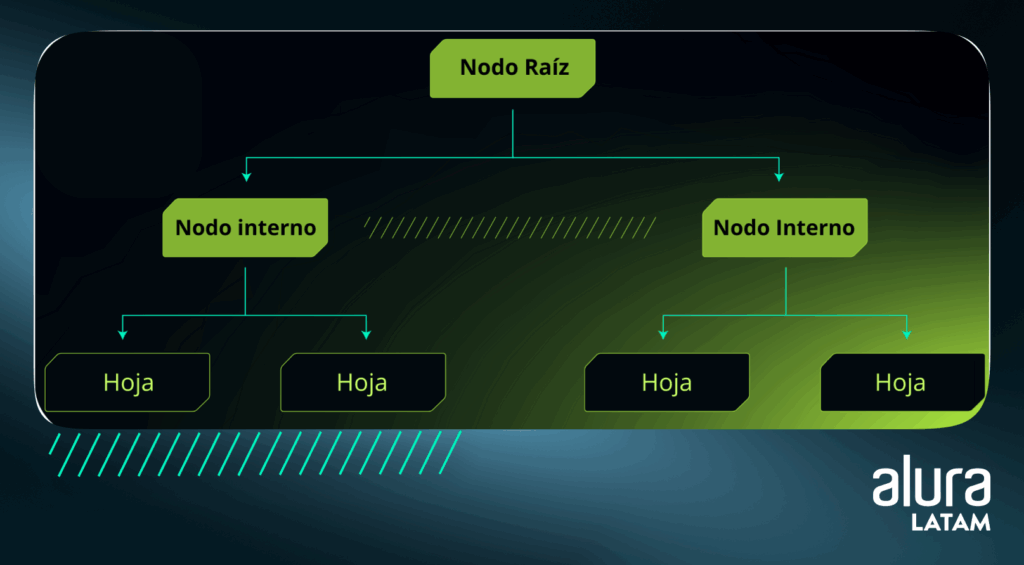
La estructura de un árbol de decisión se asemeja a un árbol común, comenzando con la raíz del árbol, que es el nodo superior y representa todo el conjunto de datos.
A partir de ahí, el árbol se ramifica en nodos de decisión, que representan las elecciones que se pueden hacer en función de las variables de entrada.
Cada nodo de decisión tiene ramas que representan las diferentes opciones que se pueden elegir. Estas bifurcaciones conducen a otros nodos de decisión o nodos hoja, que representan los resultados finales.
Los nodos hoja son los nodos finales del árbol y representan los resultados finales del análisis. No tienen ramas que salgan de ellos. Cada nodo hoja representa una clase, en caso de problemas de clasificación o de valor de salida, en problemas de regresión.
Random Forest
Random Forest es un algoritmo de aprendizaje automático supervisado que destaca por su diversidad.
Al entrenar, en lugar de utilizar todos los datos disponibles, selecciona aleatoriamente muestras del conjunto de entrenamiento.
Del mismo modo, a la hora de construir cada árbol, el algoritmo no tiene en cuenta todas las variables, sino que elige, al azar, algunas de ellas para determinar los mejores nodos.
Este proceso añade una capa de aleatoriedad y diversidad al modelo, lo que ayuda a evitar el enfoque excesivo en un conjunto específico de variables y, en consecuencia, el sobreajuste.
La selección aleatoria de variables y muestras puede parecer extraña a primera vista, pero es altamente efectiva. Esta estrategia da como resultado varios árboles, cada uno con pequeñas imperfecciones aleatorias, lo que evita el sobreajuste de un conjunto particular de datos.
La pluralidad de árboles contribuye a la robustez del modelo, y al final, los árboles combinan sus predicciones para generar un resultado más fiable, ya sea promediando las predicciones en problemas de regresión o seleccionando el resultado más común en problemas de clasificación.
Agrupamiento de K-medias
El algoritmo K-Means Clustering es una técnica de aprendizaje no supervisado que agrupa un conjunto de datos sin etiquetar en diferentes clústeres.
En este método, el valor K (número de clústeres deseados) está predefinido por el experto, lo que indica cuántos grupos se crearán durante el proceso.
El algoritmo funciona de la siguiente manera: primero, el usuario especifica el número deseado de clústeres (K), para explicar consideremos .K = 3
A continuación, el algoritmo selecciona aleatoriamente 3 puntos (K puntos) del conjunto de datos como centros iniciales de los clústeres.
Con cada iteración, cada punto de datos se asigna al clúster cuyo centro está más cerca. A continuación, los centros de los clústeres se vuelven a calcular en función de los puntos asignados a ellos, y el proceso se repite hasta que la asignación de los puntos a los clústeres no cambia significativamente entre iteraciones. Así, al final tendremos 3 clústeres:
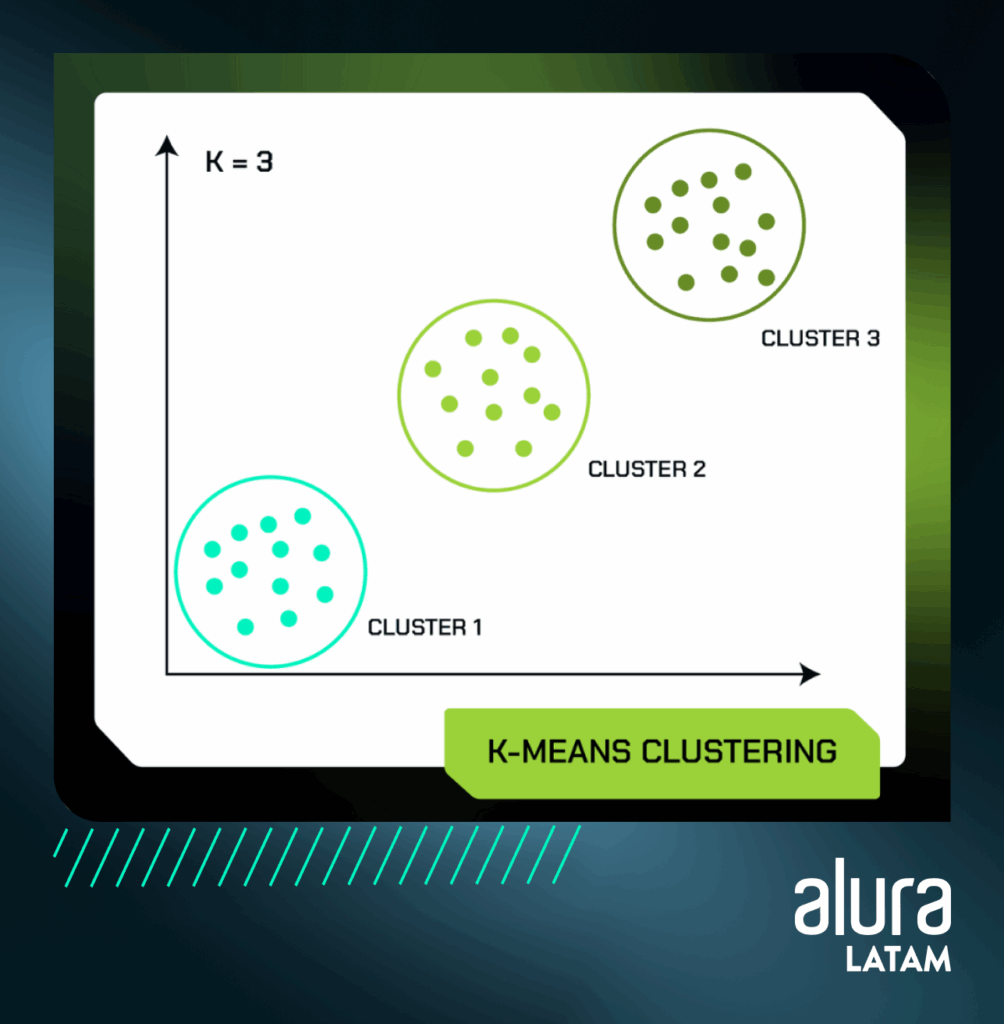
Al final, este algoritmo divide el conjunto de datos en 3 clústeres (K clústeres) para que cada clúster pertenezca a un solo grupo con propiedades similares.
La idea principal es minimizar la suma de las distancias entre los puntos de datos y los centroides correspondientes.
Redes neuronales
Originadas a partir de un simple perceptrón, las redes neuronales artificiales son una arquitectura fundamental que sirve de base para redes neuronales más avanzadas. A pesar de que existen Redes Neuronales Simples, son las Redes Neuronales centradas en el Aprendizaje Profundo las que llevan la fama de las Redes Neuronales. Conozcamos los más notables:
Redes neuronales feedforward (FF)
Las redes neuronales feedforward son una de las formas más antiguas de redes neuronales. En este tipo de arquitectura, los datos fluyen en una sola dirección, pasando a través de diferentes capas de neuronas artificiales hasta conseguir el resultado deseado.
Cada capa procesa la información y la transfiere a la siguiente capa sin formar bucles de retroalimentación, lo que la hace efectiva en tareas como la clasificación y la regresión, donde los datos se pueden representar como entradas independientes y el orden de las entradas no tiene un significado especial, como los datos no secuenciales.
Redes neuronales recurrentes (RNN)
Las redes neuronales recurrentes están diseñadas para manejar datos secuenciales, como series temporales. Introducen la idea de "memoria" en las redes neuronales, donde las salidas anteriores influyen en las salidas futuras. Sin embargo, las RNN enfrentan desafíos de retención de información a largo plazo.
Memoria a Largo/Corto Plazo (LSTM)
Los LSTM son una forma avanzada de RNN que aborda el problema de corto alcance de la retención de información. Son capaces de "recordar" eventos importantes de capas anteriores, lo que permite la manipulación eficaz de datos secuenciales más extensos.
Esta capacidad de retener información a largo plazo hace que los LSTM sobresalgan en tareas complejas como la traducción automática y la generación de texto para predecir la próxima letra.
Redes Neurais Convolucionales (CNN)
Las redes neuronales convolucionales se emplean ampliamente en tareas de visión artificial.
Con una arquitectura compuesta por capas convolucionales y de agrupación, las CNN son eficientes en la extracción de patrones espaciales en los datos, lo que las hace ideales para el procesamiento de imágenes.
Aplican filtros para identificar características relevantes antes de pasar a capas totalmente conectadas para la toma de decisiones.
Redes generativas adversarias (GAN)
Las redes generativas adversarias adoptan un enfoque que involucra dos redes neuronales, una generativa y otra discriminadora, que compiten entre sí. El generador crea datos que intentan ser idénticos a los datos reales, mientras que el discriminador intenta diferenciarlos.
Los datos creados y desglosados pueden ser imágenes, audios, videos e incluso textos, todo depende del objetivo de la GAN. Esta competencia da como resultado un aprendizaje más refinado, que se utiliza en aplicaciones como la generación de imágenes y la traducción de estilos.
Ventajas y desventajas de ML
El uso y desarrollo del Machine Learning tiene varias ventajas y desventajas. Entre las ventajas podemos enumerar:
- Los modelos de aprendizaje automático pueden analizar grandes conjuntos de datos e identificar patrones complejos, lo que mejora la precisión de la toma de decisiones.
- El ML automatiza las tareas repetitivas y que requieren mucho tiempo, lo que aumenta la eficiencia operativa.
- Los algoritmos de ML se pueden entrenar con nuevos datos, lo que los hace adaptables a las condiciones ambientales cambiantes.
- El aprendizaje automático es eficaz para reconocer patrones y tendencias en los datos, lo que ayuda a predecir resultados futuros.
Como desventajas, podemos mencionar:
- Si los datos utilizados para entrenar modelos contienen sesgos, el aprendizaje automático puede reproducir y amplificar estos sesgos, lo que puede dar lugar a resultados discriminatorios.
- Algunos modelos de ML, especialmente los más complejos, pueden ser difíciles de interpretar cómo funcionan, lo que puede dificultar la comprensión de cómo se toman las decisiones.
- El rendimiento de los modelos de ML depende de la calidad de los datos utilizados en el entrenamiento. Los datos inexactos o sesgados pueden dar lugar a predicciones incorrectas.
- El uso extensivo de datos puede generar preocupaciones sobre la privacidad, especialmente cuando se trata de datos personales confidenciales.
Carreras en Machine Learning
El mercado del Machine Learning es relativamente nuevo, pero tiene un buen potencial de crecimiento. De la mano de la llegada de las Inteligencias Artificiales al mercado tecnológico, el Machine Learning ha conseguido destacar en la demanda de personas especializadas en este campo. Actualmente existen carreras en las que el ML está presente en su campo de actividad.
Carrera de Científico de Datos
Inicialmente, el científico de datos se centró en realizar análisis descriptivos y desarrollar modelos estadísticos, pero posteriormente su rol se amplió para realizar también la creación de modelos de Machine Learning.
En la actualidad, una persona Data Scientist necesita saber realizar con maestría tareas como la recopilación de datos, la limpieza de datos y el procesamiento de datos, buscando preparar un conjunto de valores para ser transformados en información útil. Con los datos listos, este profesional puede realizar análisis y desarrollar modelos de Machine Learning.
¿Cómo es el día a día de una Científica de Datos?
Centrándose en las habilidades relacionadas con el aprendizaje automático, un científico de datos comprende los fundamentos estadísticos detrás de los modelos de ML y tiene la capacidad de aplicar técnicas avanzadas de aprendizaje automático para resolver problemas específicos.
Para ello, tienen sólidas habilidades de programación y están familiarizados con bibliotecas y marcos relevantes para el aprendizaje automático.
Dudas de Principiantes en Data Science #AluraTips
Además de las habilidades técnicas, los científicos de datos son verdaderos <profesionales de TI> porque además de necesitar colaborar con otros equipos, como ingeniería de software, análisis de negocios e ingeniería de datos, asegurando que los modelos desarrollados se alineen con los objetivos y necesidades generales de la organización, también deben tener la capacidad de traducir conocimientos complejos a un lenguaje que sea comprensible para las partes interesadas y no técnico.
¿Cómo ser un Profesional en T? Conociendo al Tech Guide
Carrera de ingeniería de ML | MLOps
El ingeniero de aprendizaje automático desempeña un papel crucial en la integración de modelos de aprendizaje automático en los sistemas existentes, combinando habilidades de ingeniería de software, ciencia de datos y DevOps.
En este rol, es esencial garantizar la armonía entre los modelos de ML y los sistemas de producción, facilitando el consumo de datos y el entrenamiento. Además, un profesional es responsable de monitorear continuamente el rendimiento de los modelos, lo que requiere una automatización eficiente para los ajustes y el reentrenamiento, asegurando que la precisión se mantenga a lo largo del tiempo.
Este puesto híbrido requiere sólidas competencias en estadística, ciencia de datos y programación, destacándose por sus habilidades de ingeniería de software.
Un ingeniero de ML actúa como enlace entre varias áreas, colaborando estrechamente con los equipos de Ingenieria de Datos, desarrollo de software y equipos de DevOps.
Su capacidad para comunicarse y trabajar en equipo es fundamental, ya que el profesional de ingeniería de ML es intrínsecamente multidisciplinar, desempeñando un papel central en la comunicación entre las áreas técnicas y de datos.
En las organizaciones más pequeñas, este profesional también puede asumir los roles de un científico de datos, lo que refleja la versatilidad y adaptabilidad necesarias para mantener los sistemas de producción de ML eficientes y en perfecto estado de funcionamiento.
A medida que la automatización de los algoritmos de ML continúa evolucionando, crece la relevancia y la demanda de ingenieros de aprendizaje automático, lo que representa una profesión en constante prominencia y maduración en el panorama tecnológico.
Carrera como investigador de ML
En la medida en que haya espacio para el descubrimiento de nuevas tecnologías, sistemas y métodos, habrá un investigador. Un investigador de aprendizaje automático busca nuevos algoritmos y aplicaciones en el mercado.
Muchas empresas de tecnología invierten en un equipo de personas que se dedican a investigar y desarrollar enfoques innovadores para desafíos específicos dentro del campo del Machine Learning.
El investigador de ML puede trabajar en diversas organizaciones, como empresas de tecnología, industrias, instituciones académicas y agencias gubernamentales.
En general, una persona profesional en este campo realiza estudios, experimentos y análisis en profundidad para avanzar en el estado del arte, contribuyendo al desarrollo teórico y práctico del campo de estudio de la organización de la que forma parte.
El futuro del Machine Learning
Ahora que conocemos bien el tema del Machine Learning, ¿qué tal si comprobamos las posibilidades para el futuro del ML?
¿Cuáles son las tendencias para el campo del Machine Learning?
Creo que una tendencia a futuro, y que ya estamos siguiendo, es el avance de los LLM, como GPT-4. Herramientas como esta han transformado la forma en que entendemos e interactuamos con los datos, lo que abre la puerta a varias aplicaciones. Además, con el aumento de la complejidad de los modelos, se ha puesto en primer plano la cuestión ética. La protección de datos, la promoción de la diversidad y la mitigación de sesgos, la creación de algoritmos más justos y responsables se han vuelto cada vez más importantes.
¿Cuáles son los desafíos más importantes para las personas que trabajan en esta área?
La dimensión ética es un punto muy importante que requiere una reflexión constante sobre la responsabilidad en el desarrollo de un algoritmo. La reestructuración organizacional para adaptarse a las nuevas IA es otro reto que puede requerir un cambio cultural y estructural en las empresas. Además, al ser una tecnología reciente, hay escasez de contenido relacionado, especialmente en portugués, lo que puede representar un desafío para aquellos que quieren sumergirse en el tema. En consecuencia, el inglés acaba convirtiéndose en un gran reto cada vez más importante.
¿Cómo impactan las nuevas tecnologías, como las IA, en el trabajo de los profesionales del Machine Learning?
Como nota positiva, estas nuevas tecnologías ayudan mucho a detallar ideas, automatizar tareas repetitivas y agilizar procesos, lo que aporta eficiencia y permite a los profesionales centrarse en aspectos más estratégicos. Sin embargo, hay algunos aspectos negativos asociados, como la posibilidad de obtener información incorrecta. Además, existen consideraciones éticas, como el uso inapropiado de las imágenes. Un ejemplo que generó muchas discusiones fue el uso de la IA en una pieza publicitaria para simular la imagen de Elis Regina, quien falleció en 1982. Se plantearon algunas preguntas sobre si el deepfake de Elis Regina constituía o no una violación ética. Se trata de una nueva tecnología demasiado alarmante, por lo que los límites en torno a ella aún se están decidiendo y es crucial mantener los debates sobre el tema.
¿Cómo mantenerse al día con tantos avances y desarrollo de nuevas tecnologías en este campo?
Asistir a eventos es crucial, no solo para mantenerse actualizado, sino también para ampliar las conexiones y la red de contactos. Además, participar en hackathons es una forma de conocer más sobre otros proyectos o puntos de la agenda, creando un portafolio y contactos con personas de la zona. Otra forma es consumir algunos contenidos de la zona en Linkedin, videos en YouTube, cursos, participación en comunidades, certificaciones, como una forma de ayudar en el conocimiento de las nuevas tecnologías.
¿Qué te parece si echas un vistazo a otros consejos y contenidos que puedes encontrar aquí en Alura?
Cursos en el área de ML
En Alura contamos con una diversidad de cursos enfocados en el tema de Machine Learning. En ellos se aprende desde los fundamentos del aprendizaje hasta la construcción de modelos más complejos.
Más información sobre el Machine Learning
Accede a la Capacitación de Machine Learning, realizadas por la Escuela de Ciencia de Datos de Alura y continúa aprendiendo sobre temas como:
- Machine Learning: Clasificación con SKLearn
- Machine Learning: Clasificación entre bastidores
- Machine Learning: Manejo de Datos de Muchas Dimensiones
- Clustering: extracción de patrones de datos
- Machine Learning: Validación de modelos
- Aprendizaje automático Parte 1: Optimización de modelos a través de hiperparámetros
- Aprendizaje automático Parte 2: Optimización con exploración aleatoria
- ¿Cómo aprender mejor? | #AluraMas
Preguntas más frecuentes:

¿Cuál es el propósito del Machine Learning?
El objetivo del aprendizaje automático es desarrollar algoritmos y modelos que sean capaces de aprender de los datos y realizar tareas específicas sin necesidad de programarlos explícitamente. Permite a las computadoras descubrir patrones automáticamente y hacer predicciones o decisiones basadas en esos patrones.
¿Cuáles son los tipos de aprendizaje automático?
Hay tres tipos principales de aprendizaje automático: el aprendizaje supervisado, en el que los modelos se entrenan con datos etiquetados para hacer predicciones o clasificaciones; el aprendizaje no supervisado, en el que los modelos encuentran patrones en los datos sin etiquetas; y el aprendizaje por refuerzo, en el que los modelos aprenden a través de prueba y error, recibiendo recompensas o penalizaciones.
¿Cuál es la diferencia entre Inteligencia Artificial y Machine Learning?
La Inteligencia Artificial (IA) es un campo más amplio que abarca diferentes técnicas y enfoques para crear sistemas que puedan simular la inteligencia humana. El aprendizaje automático, por otro lado, es un subcampo de la IA que se centra en el desarrollo de algoritmos que permitan a los ordenadores aprender de los datos y mejorar su rendimiento con el tiempo, sin ser programados explícitamente.
Machine Learning y Python: ¿Cuál es la relación?
Python es uno de los lenguajes de programación más populares para desarrollar soluciones de aprendizaje automático (ML). Ofrece una amplia gama de bibliotecas y marcos, como TensorFlow y scikit-learn, que simplifican la implementación de algoritmos de aprendizaje automático. Python es conocido por su sintaxis clara y fácil de aprender, lo que lo convierte en una opción común para los profesionales que trabajan con ML.
Deep Learning y Machine Learning: diferencias clave
Conclusión
El Machine Learning destaca como una herramienta útil en varias organizaciones y empresas para contribuir a la automatización de procesos, toma de decisiones, identificación de problemas, predicción de escenarios futuros, etc.
El avance de este campo y su gran adaptabilidad al contexto digital moderno es notable, impulsando innovaciones que van desde asistentes virtuales como Amazon Alexa hasta la identificación de fallos en líneas de producción y relleno de contenedores.
A pesar de sus desventajas, el ML ha traído casos de éxito y optimización en varios sectores. Con técnicas variadas, como la agrupación, la clasificación y la regresión, así como enfoques de aprendizaje supervisado, no supervisado, semisupervisado y de refuerzo, el aprendizaje automático contemporáneo demuestra ser muy versátil en varios problemas.
Créditos
- Criação Textual: Mirla Costa
- Participação externa - Especialista de mercado: Letícia Pires | Redes sociais: Linkedin, Instagram, Youtube
- Produção técnica: Rodrigo Dias
- Produção didática: Pedro Drago
- Designer gráfico: Alysson Manso
- Adaptación: Daysibel Cotiz
- Apoio Rômulo Henrique
