
La ciencia de datos implica una serie de procesos que incluyen la recopilación, limpieza, análisis, interpretación y visualización de datos, con el objetivo de tomar decisiones fundamentadas y resolver problemas.
Como parte de este proceso, la visualización de datos tiene un papel muy importante: transformar datos brutos en información comprensible, simple y directa mediante elementos visuales (líneas, barras, puntos, entre otros).
En este artículo, te presentaremos las principales visualizaciones de datos utilizadas en ciencia de datos, ejemplificando casos en los que pueden ser aplicadas, el objetivo de cada tipo de visualización y cómo pueden ayudarte en la ejecución de tus proyectos en tu empresa, estudios y portafolio.
Pero, ¿cómo puedo elegir el tipo de visualización más adecuado para mi proyecto y para lo que quiero representar?
La elección del tipo de gráfico adecuado está relacionada con el tipo de datos que poseemos, el objetivo que tenemos respecto al uso de ese recurso visual y la organización que deseamos para nuestros datos, con el fin de generar información relevante que pueda ayudar en la toma de decisiones o en la obtención de insights al leer los datos.
El enfoque debe ser informar solo lo necesario, evitando la distorsión de la información, la sobrecarga cognitiva — esa sensación de visual muy saturado y con más elementos de los necesarios — o provocar una interpretación errónea del análisis.
Vamos a observar una serie de visualizaciones diferentes, entender sus objetivos por separado y aprender algunas buenas prácticas para crear y mostrar estas visualizaciones.
Tipos de visualización de datos
Podemos observar un diagrama de flujo que presenta un resumen de varios tipos de gráficos con la pregunta central: “¿Qué te gustaría presentar?”
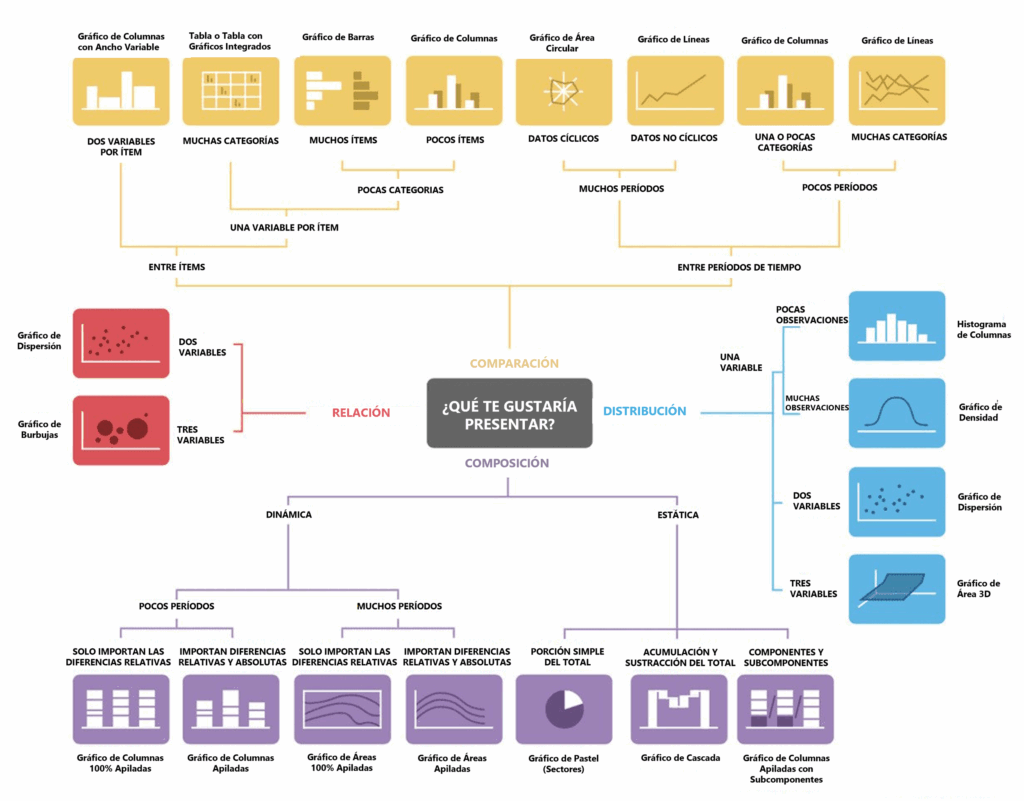
Ten en cuenta que, para cada objetivo, tenemos una serie de visualizaciones que dependen de la variedad de los datos, si son datos numéricos, categóricos o temporales, e incluso de la cantidad de observaciones.
Vamos entonces a explorar algunos gráficos de cada subgrupo: comparación, composición, distribución y relación.
Comparación de datos
La comparación de datos se refiere al análisis e interpretación de series de datos, identificando similitudes, diferencias y patrones entre ellas.
Podemos comparar diferentes valores y atributos en busca de tendencias, variaciones y relaciones entre los conjuntos de datos.
Los gráficos a continuación representan diversas formas de comparar datos, ya sea por valores numéricos, categorías y/o tiempo:
Gráfico de columnas
Un gráfico de columnas es una representación visual de valores numéricos de una o más categorías de datos, ya sean discretas o de intervalos definidos.
Se utiliza para comparar diferentes categorías o grupos de datos mediante barras verticales de forma rápida y directa.
Es uno de los gráficos más utilizados en la exploración de datos, elaboración de informes y presentaciones.
El gráfico de columnas a continuación representa el análisis de las ventas por departamento de un comercio electrónico ficticio en un determinado período de tiempo.
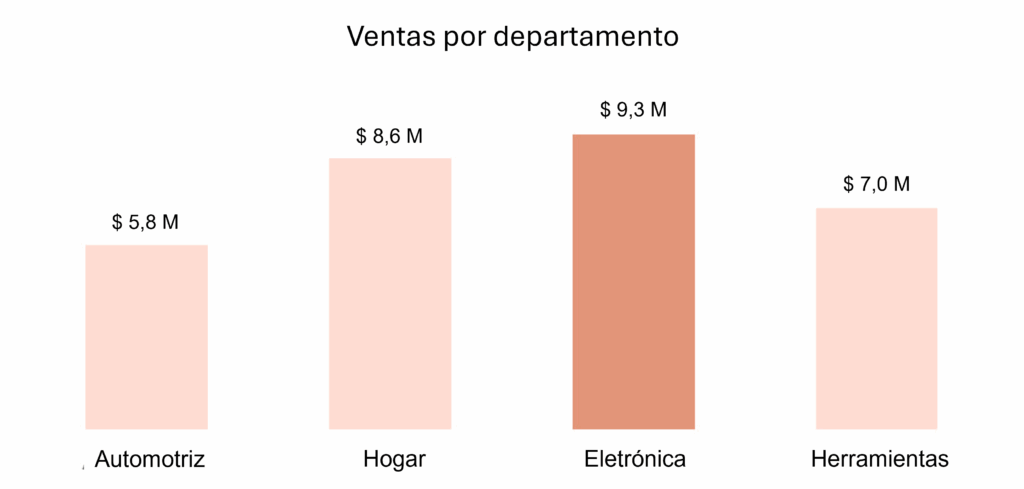
El gráfico construido destaca las ventas del departamento de Electrónica de esta empresa. Además de que la comparación entre los datos es bastante directa —ya sea por el tamaño de las columnas como por la presencia de las etiquetas en millones —, el uso de colores facilita la distinción entre las barras, haciendo que esta visualización sea fácil de leer e interpretar.
Gráfico de barras horizontales
A continuación, tenemos otra visualización muy utilizada para la comparación de datos: el gráfico de barras horizontales.
Este gráfico compara los datos de diferentes categorías o grupos, al igual que el gráfico de columnas, pero con un énfasis inicial en las categorías.
Esta visualización es más eficiente para leer etiquetas y categorías más largas, ya que permite una presentación más fluida (en horizontal) de textos que pueden ser extensos.
El enfoque principal de este tipo de gráfico está primero en la categoría de los datos y, luego, en los valores numéricos.
A continuación, tenemos un gráfico de barras horizontales que representa la población brasileña en 2022 dividida por región.
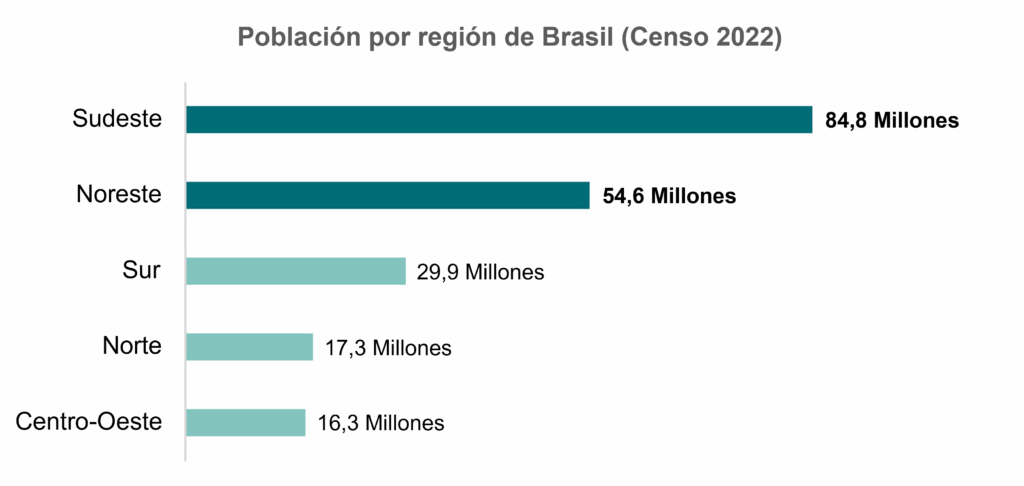
El gráfico construido destaca las poblaciones de las regiones Sudeste y Noreste, ambas por encima de los 50 millones de personas. Esta visualización en ciencia de datos es muy utilizada para comparar categorías de una o más variables mediante el conteo de veces que aparecen, tanto en conjuntos de datos pequeños como grandes, y para comunicar los resultados en el análisis exploratorio de datos.
Una buena práctica en un gráfico de barras es mantener las barras ordenadas de forma creciente o decreciente, ya que esto facilita la lectura de los datos.
Gráfico de líneas
Otra visualización ampliamente utilizada para la comparación de datos son los gráficos de líneas.
Se trata de una representación visual que conecta puntos de datos mediante líneas rectas, siendo ideal para representar tendencias a lo largo del tiempo o de acuerdo con una secuencia con orden definido.
En ciencia de datos, los gráficos de líneas se utilizan con frecuencia para visualizar series temporales, como la evolución de las ventas a lo largo de los meses —como en el gráfico a continuación— o el crecimiento de una población o muestra a lo largo de los años.
Cuando tenemos una gran cantidad de períodos en nuestros datos, vale la pena recurrir a los gráficos de línea(s) para representar las series temporales.
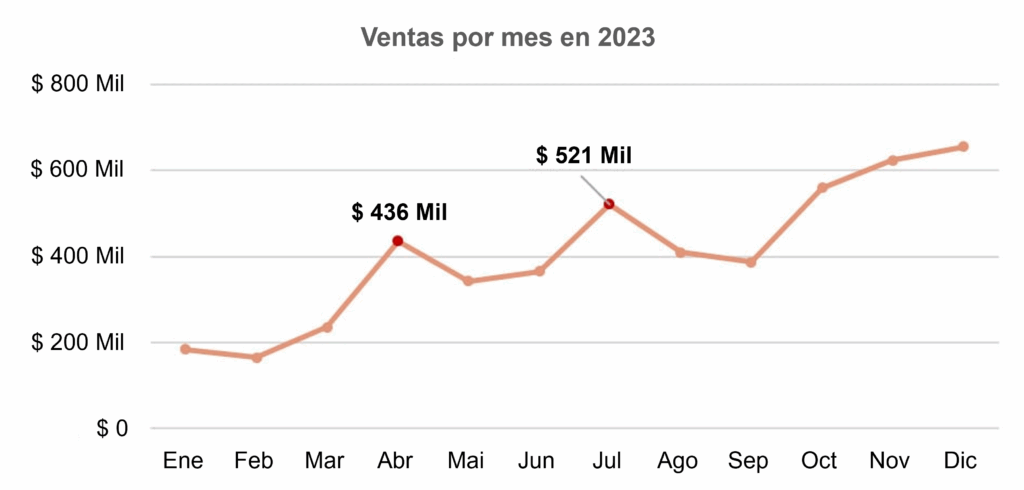
En el gráfico anterior, destacamos los valores de abril y julio de 2023 mediante el cambio de color de los puntos y la inserción de etiquetas con las ventas en miles.
Una buena práctica en este tipo de visualización es la inserción de etiquetas informativas en las partes que deseamos resaltar, el uso de rejillas para facilitar la lectura de las coordenadas de los puntos, y el cuidado en la escala de los ejes para evitar distorsiones en la interpretación de los datos.
Por su parte, un gráfico de líneas permite agregar una capa adicional de análisis mediante la inclusión de una variable categórica, lo que posibilita la comparación de las series temporales.
En el ejemplo siguiente, observamos la facturación trimestral por empresa mayorista en una ciudad ficticia.
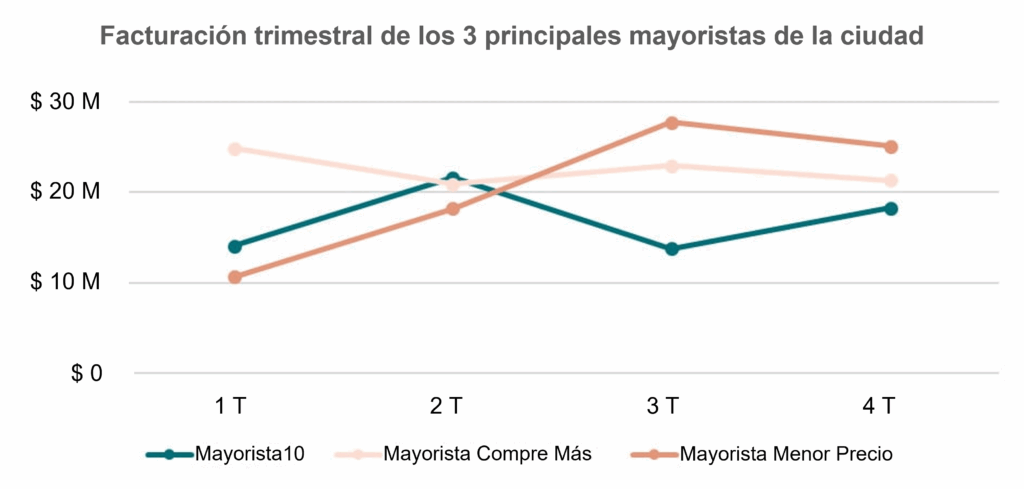
Con esta visualización, es posible comparar la facturación de cada mayorista en diferentes momentos utilizando un solo gráfico.
Hay que tener cautela al insertar etiquetas en este tipo de visualización, evitando un exceso de elementos visuales en el gráfico.
Otra buena práctica es agregar la menor cantidad de líneas posible, para no sobrecargar visualmente el gráfico y así no perder su propósito práctico.
En general, los gráficos de líneas son excelentes para resaltar patrones, identificar tendencias y obtener insights en ciencia de datos.
Gráfico de barras/columnas agrupadas
Como última visualización que exploraremos en este artículo sobre comparación de datos, existe otra forma de combinar gráficos de barras y columnas: los gráficos de barras o columnas agrupadas.
Se trata de una representación visual que organiza barras o columnas en grupos, donde cada grupo representa una categoría o variable, y las barras dentro de cada grupo representan una subcategoría o subconjunto de datos.
Un gráfico de columnas o barras agrupadas es ideal cuando se desea comparar diferentes categorías con respecto a una variable, mostrando cómo se comparan los valores dentro de cada categoría (en el gráfico siguiente, los años) mediante columnas separadas (en el gráfico, "Nuestro sitio", "Competidor A" y "Competidor B"), facilitando la visualización de patrones y diferencias entre grupos.
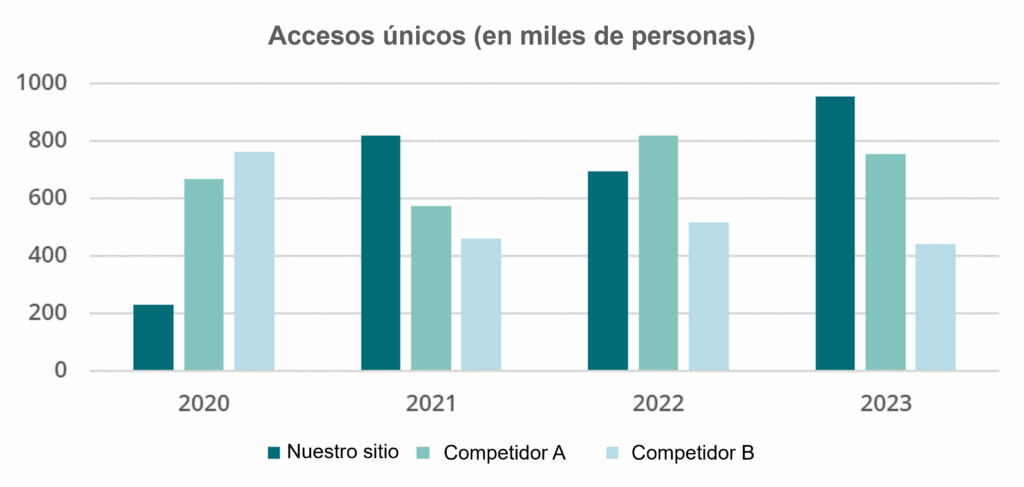
El gráfico construido presenta la evolución de los accesos únicos en la categoría "Nuestro sitio" y los compara con los accesos de dos competidores en una misma visualización.
En ciencia de datos, este tipo de gráfico es útil para comparar métricas o características de diferentes categorías en una sola visualización, por ejemplo, el desempeño de distintos productos en varias regiones geográficas a lo largo del tiempo.
Una buena práctica para un gráfico de columnas o barras agrupadas es usar colores distintos para cada grupo, organizar las columnas siempre en el mismo orden en cada categoría o período, y evitar el uso excesivo de etiquetas de datos.
Composición de datos
Pasemos ahora al segundo subgrupo de visualizaciones de datos, que es la composición de datos. En visualización de datos, se refiere a la representación de conjuntos de datos como partes de un todo, destacando la contribución de los diferentes componentes a la totalidad de los datos.
En ciencia de datos, la composición de datos se utiliza con frecuencia para analizar las características generales de categorías o subgrupos dentro de un conjunto de datos, visualizando su estructura y cómo se relacionan entre sí y con el todo.
Los gráficos que veremos a continuación representan diversas formas de mostrar la composición de datos, ya sea de forma estática (en un período fijo) o dinámica (a lo largo del tiempo):
Gráfico de pastel
Un gráfico de pastel (o gráfico circular) es una representación visual que utiliza un círculo dividido en porciones para retratar las proporciones de diferentes categorías dentro de un conjunto de datos.
Sirve para destacar la composición de las partes respecto al todo, especialmente cuando se desea enfatizar la participación porcentual de cada categoría. Es uno de los gráficos más utilizados en el día a día, aunque requiere mucha atención al construirlo.
En ciencia de datos, el gráfico de pastel se utiliza frecuentemente para visualizar la composición estática de los datos, como la composición de ingresos por categoría de productos o la participación de una categoría respecto al total, así como para comunicar resultados con pocas categorías.
El gráfico siguiente representa el resultado de una encuesta sobre la percepción de los usuarios tras una actualización de la interfaz de un sitio web.
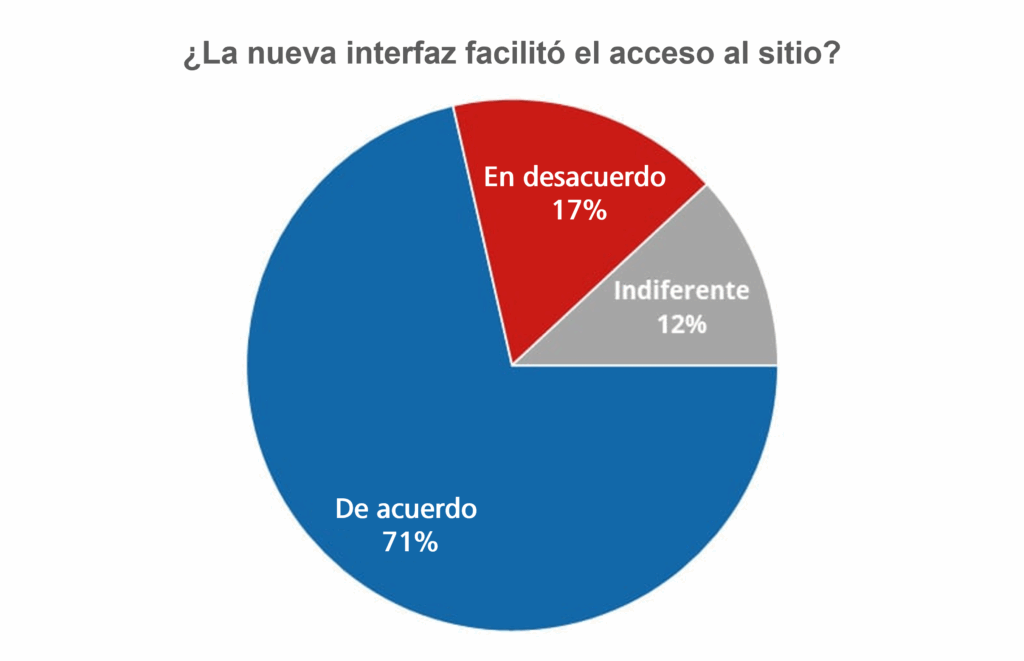
El gráfico construido muestra en valores porcentuales las respuestas de los usuarios sobre la nueva interfaz del sitio web.
Se requiere mucha precaución en su uso, evitando más de cinco porciones (categorías), así como el uso de porciones muy cercanas entre sí (por ejemplo, 51% y 49%) o muy distantes (por ejemplo, 99% y 1%).
Además, los gráficos de pastel se aprovechan mejor en datos dicotómicos (dos categorías).
Gráfico de barras apiladas
Pasemos ahora a otro gráfico de composición de datos: el gráfico de barras apiladas.
Es una representación visual que muestra la composición de diferentes categorías a lo largo de una variable independiente, como el tiempo, apilando las barras una sobre otra para representar la totalidad de los datos.
Un gráfico de barras o columnas apiladas es ideal cuando deseamos comparar distintos períodos o categorías, y al mismo tiempo, comparar los componentes que conforman cada uno de ellos.
De este modo, se puede representar tanto la contribución de cada categoría al total, como los cambios en la composición a lo largo del tiempo o según una variable específica.
En el gráfico a continuación, observamos la composición del Ingreso Bruto por Ventas de una empresa, el cual se calcula como la suma entre el Ingreso Operativo Neto (ION), los impuestos, las devoluciones de productos y los descuentos.
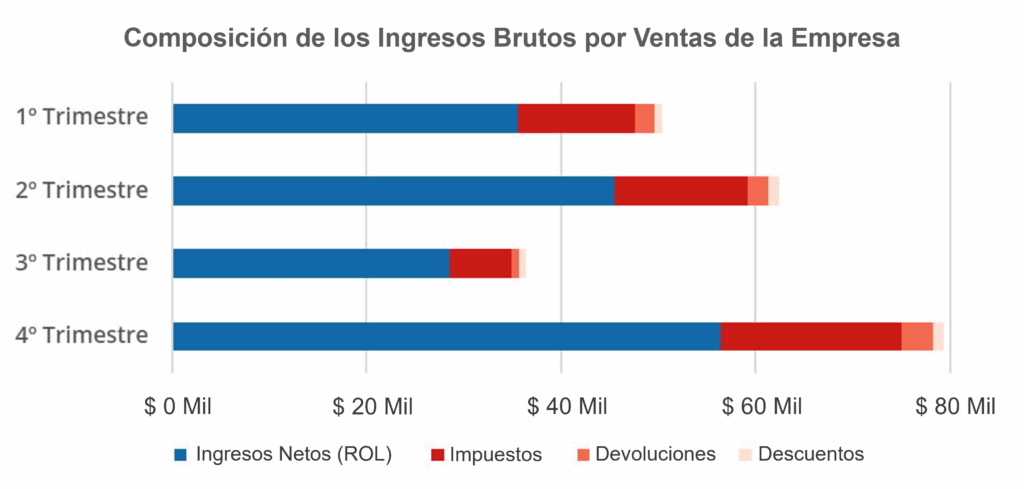
Note que el gráfico construido muestra la evolución de los Ingresos Brutos por Ventas a lo largo de los trimestres y también la composición de cada parte de los valores que lo constituyen en cada trimestre.
En ciencia de datos, los gráficos de barras apiladas se utilizan frecuentemente para comparar la distribución de datos categóricos en diferentes grupos o períodos.
Una buena práctica para un gráfico de barras apiladas es utilizar el mínimo de categorías posible para evitar contaminación visual y añadir etiquetas solo en puntos específicos donde se desea cierto destaque.
Gráfico de áreas apiladas
Similar a un gráfico de barras apiladas, el gráfico de áreas apiladas también es una representación visual que muestra la evolución de la contribución de diferentes categorías a lo largo de un período de tiempo o en relación con una variable independiente.
La diferencia está en la posibilidad de agregar más períodos de tiempo en el análisis sin insertar una serie de barras.
Aquí, un gráfico de áreas apiladas combina las características de un gráfico de líneas, siendo apiladas y con las áreas debajo de ellas rellenas, como podemos observar en el gráfico a continuación que representa el consumo de energía de una localidad por fuente renovable en valores porcentuales.
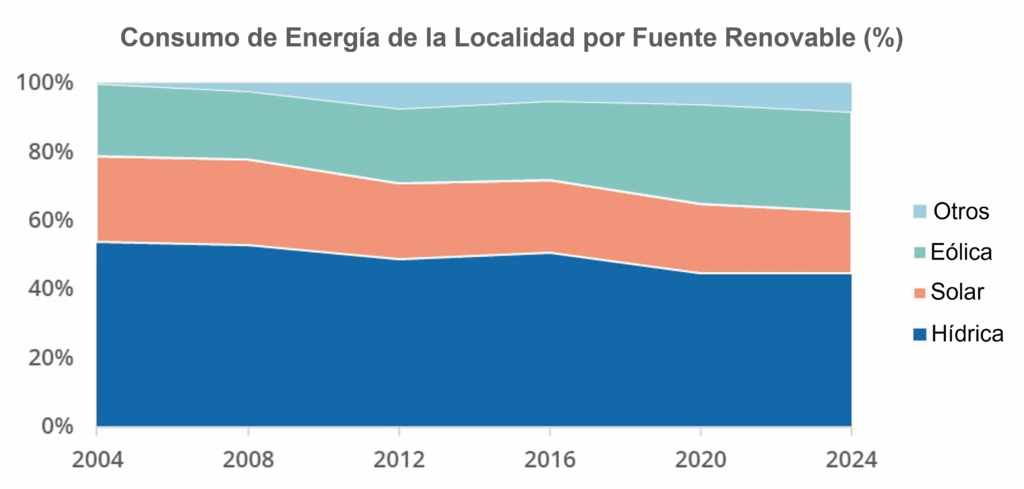
En este visual podemos percibir claramente la evolución en el consumo de energía eólica y la reducción tanto de la energía de fuente hidráulica como solar.
Es posible crear este tipo de gráfico tanto apilado con valores absolutos como en valores porcentuales, dependiendo de lo que se desea representar: la comparación entre períodos con la evolución de los valores a lo largo del tiempo o la composición porcentual a lo largo del tiempo.
Distribución de datos
Ahora, vamos al tercer subgrupo de visualización de datos, que es la distribución de datos.
Se refiere a la representación de la frecuencia o probabilidad de ocurrencia de diferentes valores en un conjunto de datos.
A través de sus visuales, podemos entender cómo se distribuyen las observaciones individuales dentro de nuestro conjunto de datos, identificando sus patrones, tendencias y características importantes.
En ciencia de datos, la distribución de datos es fundamental para comprender la naturaleza de los datos, analizando si la distribución de las variables sigue un patrón y si existen valores extremos que deben investigarse.
Además, la distribución de datos se utiliza frecuentemente en la modelización estadística y el análisis predictivo para ajustar modelos a los datos y realizar predicciones.
Los gráficos a continuación representan diversas formas de distribuir los datos, ayudando a las personas científicas de datos a entender la variabilidad, identificar outliers (valores atípicos) y tomar decisiones basadas en los patrones observados:
Histograma
Un histograma es una representación visual que muestra la distribución de los datos en un intervalo determinado.
Divide los datos en intervalos, llamados “bins”, que muestran cuántas observaciones están presentes en ese rango de datos.
Los histogramas también ayudan a identificar tendencias centrales, variabilidad, simetría de los datos y posibles valores atípicos.
En ciencia de datos, los histogramas se utilizan ampliamente para explorar la distribución de variables numéricas, como edad, ingresos, temperatura, entre otras.
En el gráfico a continuación, representamos el número de clientes por rango de edad.
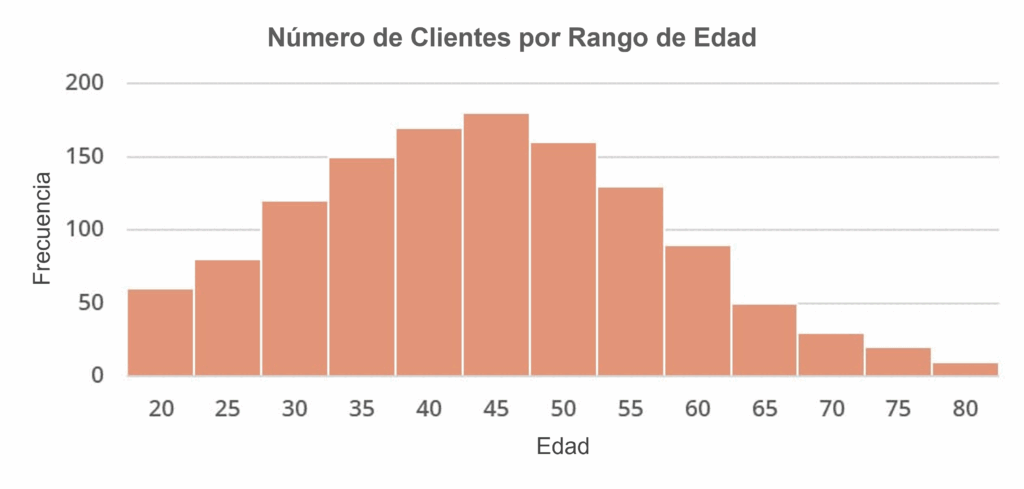
En el gráfico construido, percibimos una mayor concentración de clientes entre los 35 y 50 años (más de 150 personas por rango).
Una buena práctica para un histograma es encontrar un equilibrio adecuado entre el número de “bins” y el ancho de los mismos para representar los datos sin que los intervalos sean demasiado pequeños (bins estrechos que pueden generar ruido por tener pocas observaciones en determinados rangos) o demasiado grandes (bins amplios que pueden distorsionar la forma de la curva y reducir la sensibilidad a las variaciones entre los rangos).
Gráfico de densidad
Un gráfico de densidad es una representación visual de la distribución de probabilidad de una variable continua.
Presenta la densidad de probabilidad a lo largo del eje horizontal, donde el área total bajo la curva es igual a 1.
El gráfico de densidad ayuda a visualizar la forma y la suavidad de la distribución de los datos, así como a identificar picos, asimetrías y colas.
En ciencia de datos, los gráficos de densidad se utilizan frecuentemente para visualizar la distribución de variables numéricas y comparar la distribución entre diferentes grupos o categorías.
En el gráfico a continuación, representamos la distribución de salarios en una localidad, partiendo de 2.000 hasta 16.000.
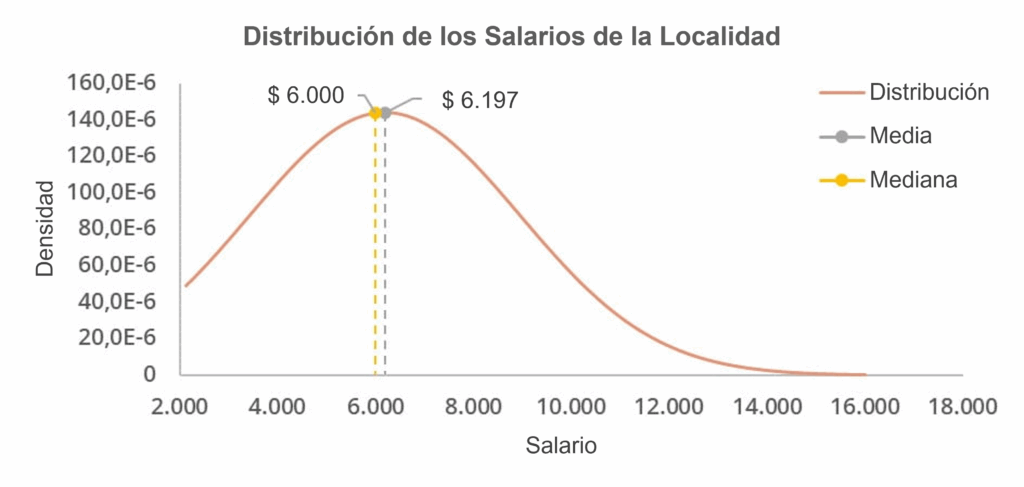
En el gráfico construido, observamos una mayor concentración de los salarios hacia la izquierda del gráfico, con la media y la mediana de los salarios en 6.197 y 6.000, respectivamente.
Una buena práctica para el gráfico de densidad es elegir un nivel de suavizado adecuado para la curva de densidad, ajustar el ancho de banda del suavizado para capturar adecuadamente las variaciones en los datos y proporcionar una leyenda que permita distinguir claramente la información.
Boxplot y Violinplot
Un boxplot (diagrama de caja) es una representación visual que muestra la distribución de un conjunto de datos mediante una serie de estadísticas descriptivas: cuartiles, mediana, mínimo, máximo y valores atípicos (outliers).
Ayuda a visualizar la dispersión y la centralidad de los datos, identificando asimetrías, outliers y variaciones.
Por su parte, el violinplot (diagrama de violín) es una versión más detallada del boxplot, que no solo muestra los cuartiles, sino también la distribución de los datos mediante la forma y suavidad de la densidad.
En ciencia de datos, ambos se utilizan para visualizar la distribución de variables numéricas y comparar distribuciones entre distintos grupos o categorías.
En el gráfico a continuación, podemos observar las similitudes y diferencias entre el boxplot y el violinplot en la distribución de las evaluaciones de un determinado producto.
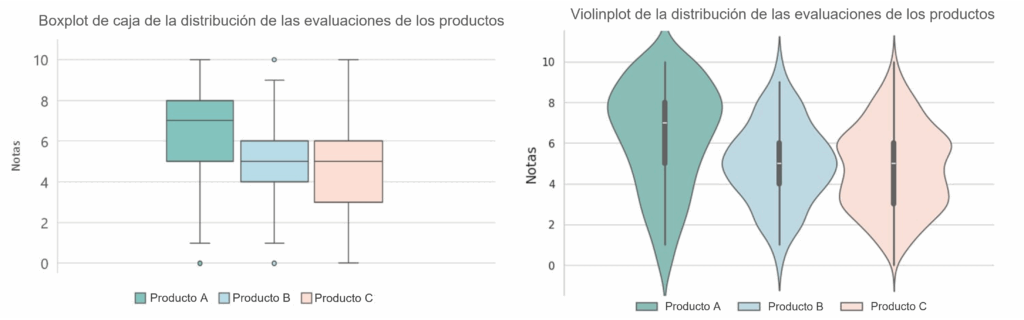
Observa que, en el gráfico de la izquierda, podemos ver algunos elementos de cada producto: límite inferior y superior antes de los outliers (líneas horizontales que delimitan los extremos fuera de las cajas), 1.º, 2.º y 3.º cuartil (límite inferior, línea interna y límite superior de la caja, respectivamente) y puntos fuera de los límites (outliers).
En el gráfico de la derecha, podemos notar pequeños boxplots representados dentro de las curvas que indican la distribución de las evaluaciones.
Podemos observar que el gráfico de la izquierda se enfoca en los valores de las estadísticas descriptivas y el gráfico de la derecha en la curva de densidad de la distribución.
Relación de datos
Pasamos entonces al 4.º y último subgrupo de visualización de datos de este artículo: la relación de datos.
Se refiere a la representación visual de las relaciones entre diferentes variables dentro de un conjunto de datos.
Puede abarcar correlaciones, asociaciones o dependencias entre las variables a través de visualizaciones de este tipo.
En ciencia de datos, entender la relación entre variables es muy importante para identificar patrones, tendencias e insights relevantes dentro de los datos.
Estas visualizaciones ayudan a las personas científicas de datos a explorar cómo las variables están interconectadas y cómo se influyen entre sí.
Además, los análisis de relación de datos son esenciales para la modelización predictiva, segmentación de mercado, identificación de influenciadores y toma de decisiones basadas en datos.
Los gráficos a continuación representan algunas de las formas de relacionar los datos, ayudando a las personas científicas de datos a investigar la relación y la intensidad entre los datos, y cómo estos pueden afectar a su proyecto:
Gráfico de dispersión
Un gráfico de dispersión es una representación visual que muestra la relación o distribución entre dos variables numéricas en un conjunto de datos.
Cada punto en el gráfico representa la combinación entre las coordenadas de las dos variables, también conocidas como observaciones.
Se utiliza ampliamente en ciencia de datos, ya que es una visualización que ayuda a identificar asociaciones o patrones, tendencias y correlaciones entre variables, lo cual es de suma importancia para el aprendizaje automático (ML).
El gráfico a continuación ilustra un ejemplo en el que utilizamos un gráfico de dispersión para visualizar la relación entre el tiempo de entrega de un producto y la satisfacción del cliente en la evaluación de la entrega.
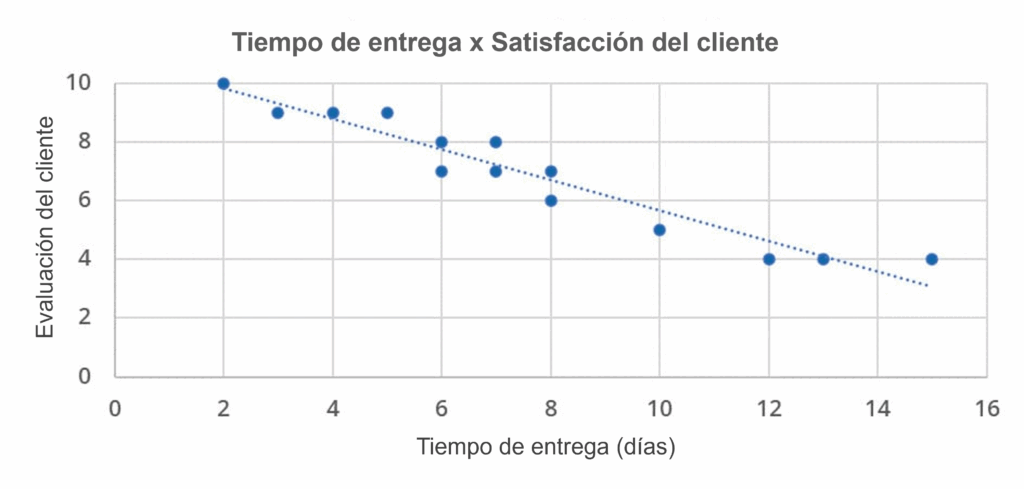
En el gráfico construido, percibimos una tendencia inversamente proporcional (negativa) entre el tiempo de entrega y la evaluación: cuanto mayor es el tiempo de entrega, la tendencia es a una menor evaluación.
Es importante inferir que esto no significa que una variable cause un efecto en la otra, sino simplemente que existe una relación y cuál es la intensidad de esa relación.
Una buena práctica para el gráfico de dispersión es la elección adecuada de las escalas de los ejes y destacar puntos o regiones de importancia en tu análisis.
Además, también es importante verificar la presencia de outliers y evaluar la naturaleza de la relación entre las variables antes de sacar conclusiones.
Matriz de correlación
Nuestro último visual es la matriz de correlación de los datos. Es una representación visual similar a una tabla que muestra la correlación entre variables numéricas o categóricas nominales en un conjunto de datos.
La matriz presenta los coeficientes de correlación entre todas las combinaciones de variables, variando de -1 a 1, donde -1 indica una correlación negativa perfecta, 1 indica una correlación positiva perfecta y 0 indica ausencia de correlación.
Esta escala sirve para identificar patrones de asociación entre variables, ayudando a entender cómo se relacionan entre sí.
Es ampliamente utilizada en modelos de aprendizaje automático en ciencia de datos, explorando la relación entre variables e identificando cuáles tienen mayor influencia unas sobre otras.
La matriz de correlación puede ser útil en el análisis exploratorio y en la selección de variables para la modelización predictiva.
En el gráfico a continuación representamos una matriz de correlación para 4 variables:
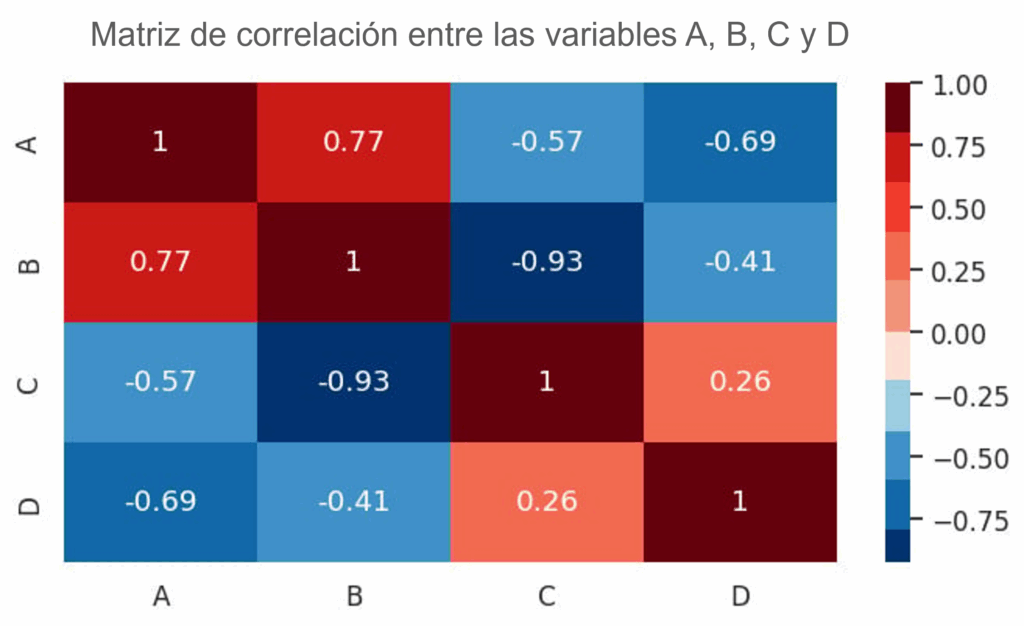
El visual construido muestra los coeficientes de correlación entre los datos, como por ejemplo, una correlación fuertemente negativa entre las variables B y C.
Como buenas prácticas para este tipo de visual, es importante elegir el método adecuado para el cálculo de la correlación, dependiendo de la naturaleza de los datos, comprender el contexto para interpretar las relaciones y utilizar mapas de calor, como en el gráfico anterior, para interpretar más rápidamente los resultados de la matriz.
Conclusión
Has notado, por lo tanto, que aquí hablamos sobre una serie de visualizaciones que parten de gráficos orientados a la comparación, composición, distribución y relación de los datos.
Vimos qué representa cada subgrupo, cuáles visualizaciones son las más adecuadas para tu objetivo de análisis o presentación de resultados, y algunas buenas prácticas a lo largo del camino.
Pero te recomiendo que no te detengas aquí y aproveches para estudiar con nosotros la formación en Data Science, con nuestro equipo de especialistas que te ayudará a impulsar tu carrera y te capacitará para tomar las mejores decisiones sobre qué gráficos utilizar para representar tus proyectos, ideas y datos.
Comparte también este artículo con tus amistades, colegas y personas que puedan estar interesadas en el tema.
Créditos
Contenido: Afonso Augusto Rios
Producción técnica: Rodrigo Dias
Producción didáctica: Tiago de Freitas
Diseño gráfico: Alysson Manso
Adaptación: Samantha Faustino
